论文:《Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation》,2022年
这篇文论对生成模型的(句子级)重复生成问题做了一些实验和分析,找到一些和重复生成现象相关的发现,并提出DITTO(pseuDo-repetITion penalizaTiOn)缓解重复生成的问题。(这缩写的方式让人想起 NEural contextualiZed representation for cHinese lAnguage understanding)
这样的研究基于一个前提:使用maximization-based decoding算法(如greedy decoding)。一些带有随机性的算法本身是具有缓解重复生成问题的能力的。
发现一:模型倾向于提升前面出现过的句子的生成概率
并且只要重复一次,这个概率就会飙升很多(下图)。这个发现和induction heads中的类似。
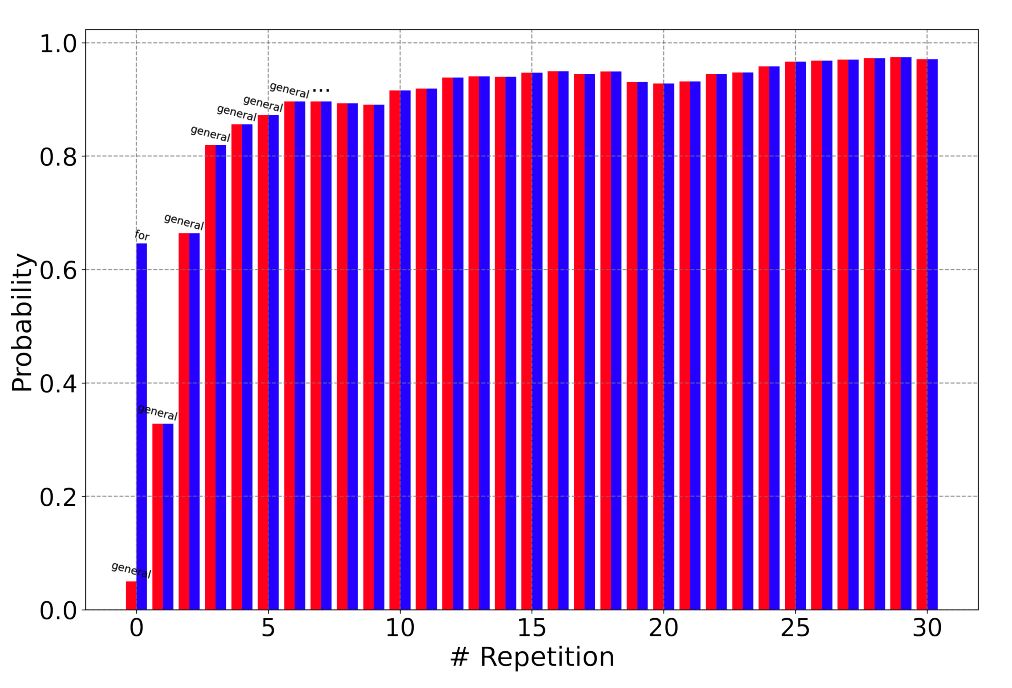
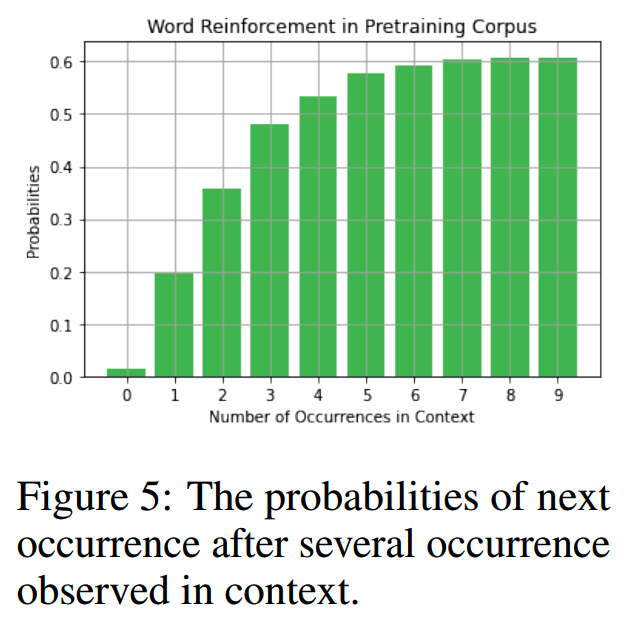
发现二:重复生成具有self-reinforcement的特点
重复的次数越多,越容易重复,越难以打破这个循环,如下图,横轴表示重复次数,纵轴红色表示某个token的概率,蓝色表示最大的概率。
发现三:Sentences with higher initial probabilities usually have a stronger self-reinforcement effect
句子本身概率越大(模型认为越通顺),重复的自我加强效应越强。把重复的句子换成随机token,在不同重复次数下解码token的概率变化如下图,增强的趋势比上图(通顺句子)要弱很多
而DITTO的做法简单来说是构造了一些重复句子的训练样本,并在训练时显示加入对重复token的惩罚。
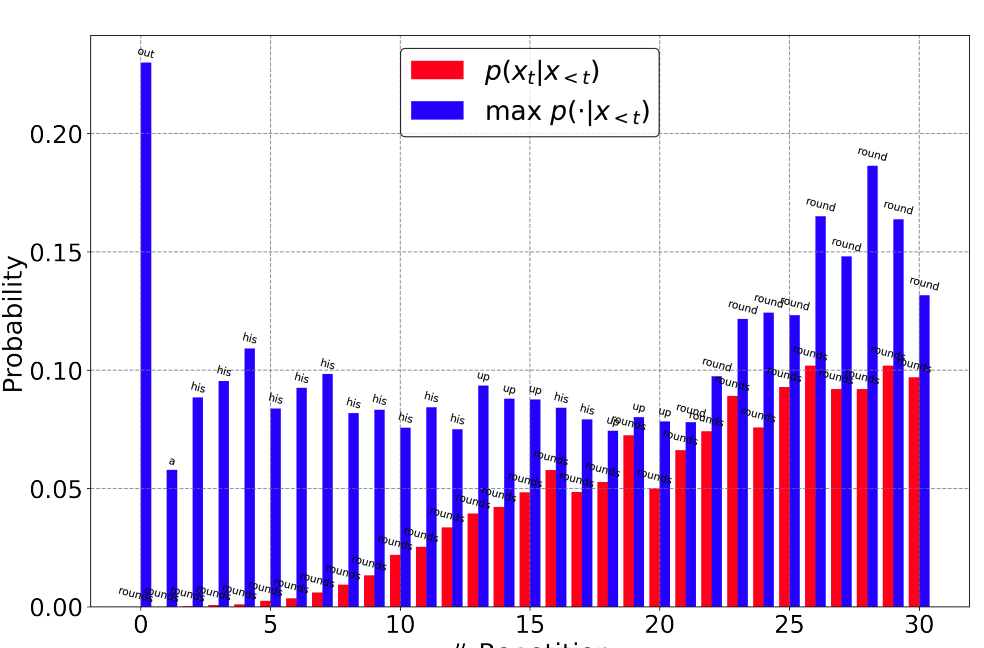
另一个工作《UNDERSTANDING IN-CONTEXT LEARNING FROM REPETITIONS》,对self-reinforcement进行了进一步的测试,发现:

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡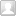 发表于 2025-2-20 13:40
发表于 2025-2-20 13:40




 提升卡
提升卡


