▲在厕所 A 和在厕所 B 排队的人在下一时刻的不同选择的概率的示意图
厕所 A 比较受欢迎,在所有到厕所 A 的人里面,下一时刻有 60% 的人会选择——就是你了,不管怎样都要排队等候。而还有 40% 的人可能因为人太多等原因选择另外一个厕所。厕所 B 则不那么受欢迎,在所有到厕所 B 的人里面,只有 30% 的人选择继续等候,剩下 70% 的人要溜。
和上一节中的计算相同,无论开始时候两个厕所外排队人数如何,经过多次选择以后,B 占比约为 36.4%,而 A 占比为 63.6%,也就是最终的状态会停留在 4:7,正好和两个厕所中间的转移的概率成正比。
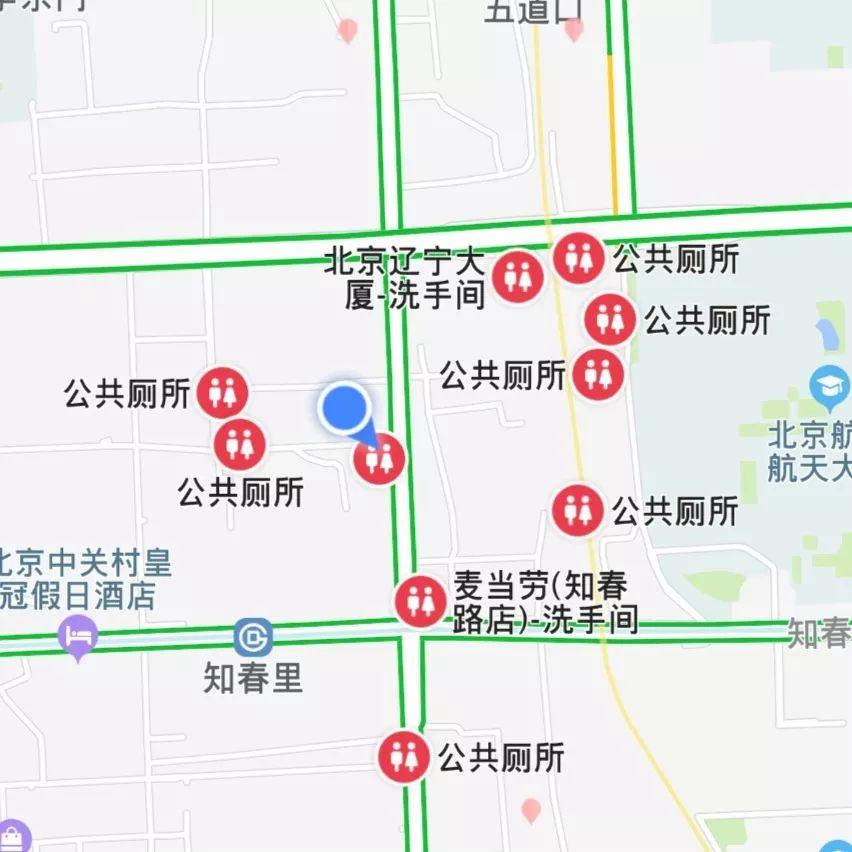
▲选麦穗策略示意图,假设 A > B > C,我们拒绝掉最开始的第一个,那么会有一半的概率选到整个序列中的最大值。
传统的选麦穗问题套路很简单,最优的策略为拒绝掉开始的所有 r - 1 个选择,在这之后,一旦遇到比之前所有都好的,直接决定。利用这种策略得到了最佳选择需要满足两个条件:
第 i 个为最佳选择
前 i - 1 个选择的最大值被我们拒绝掉了,也就是在开头的 r - 1 个里面。这样我们才能一直看到第 i 个选项
由此我们可以得到计算这个策略成功的概率为 [2]
如果希望最后选中最佳选择的概率最大,我们大约需要拒绝 1 / e ,也就是 37% 的选择。
但是,在找厕所的路途之中,我们完全可以回过头来选择之前已经遇到的最好的,这并不是一件丢脸的事情。在我们的找厕所的方法里,这个 1 / e 原则很可能有点水土不服了。 4 好马要吃回头草
我们这时候新的策略完全就是「吃回头草」。在观察完 k 个选项以后及时止损,回头选择已经看到的最好的那个。
一共有 N 个选择,我们同样先看前 r 个选项,记录最佳的结果。接下来在第 k 个(我们选择的终点)之前,一旦我们遇到了比记录结果更好的,直接选择。但是如果我们没有找到更好的,那就回头,从过去的 N - k 个选项里面选择最好的。
这个策略和之前的至多都只能做 N 个选择,在这点上两者是公平的,唯一的区别在于能不能回头。
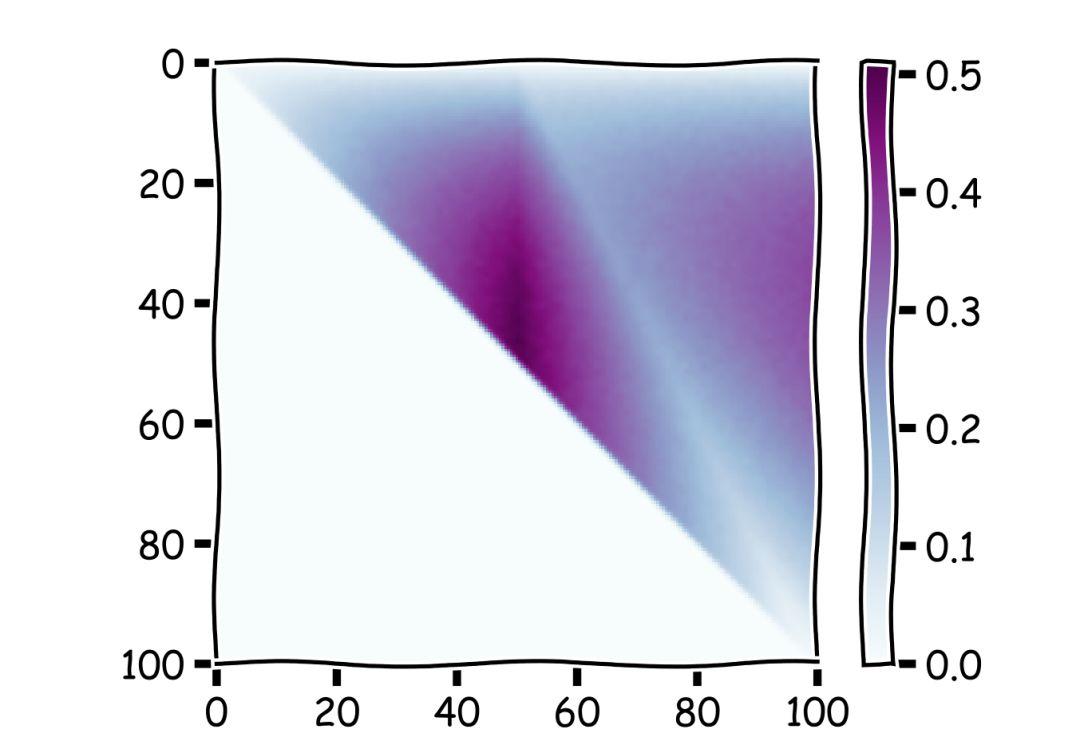
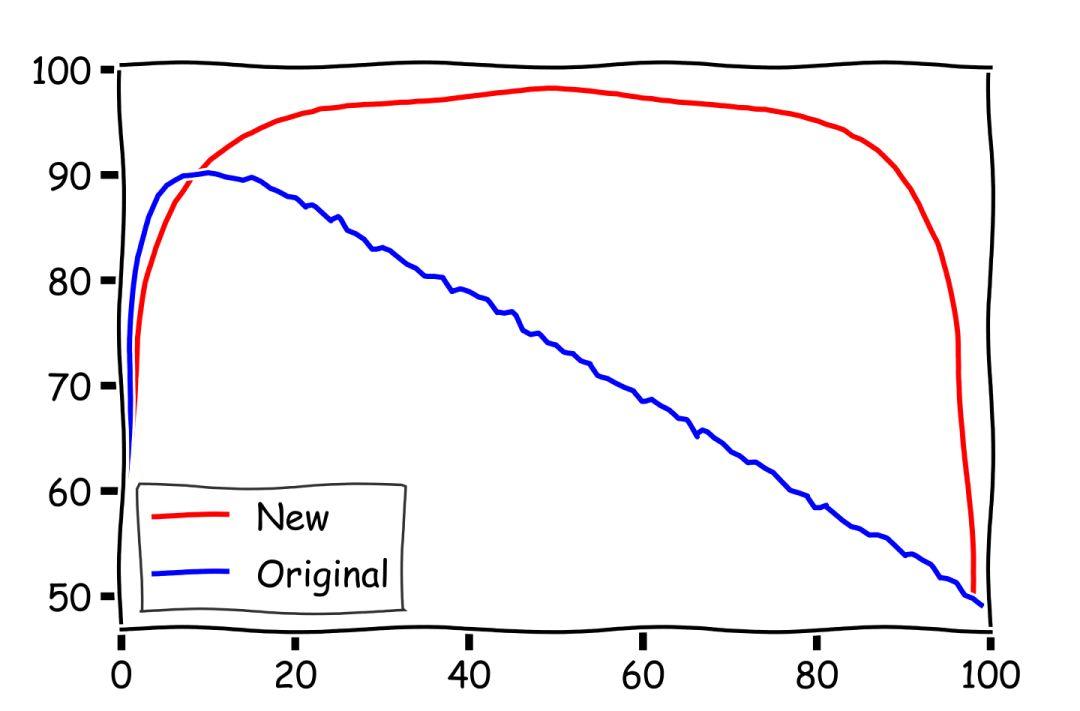
为了直观了解两个策略哪个更强,我们人为地随机生成了 10000 个长度为 100 的序列进行模拟,按照原来的 1 / e 策略和我们的吃回头草策略从序列中找出最大值。下图中横轴为 k 的取值,也就是选择的终点,到达这里以后就不再继续看新的选项了。纵轴为 r 的取值,在一开始需要拒绝的选项的数量。因为我们选择的终点显然要大于需要拒绝的数量,所以在我们的结果中只展示了上面半个三角形的部分。图中颜色的深浅代表了在这个参数下取到最大值,捡到最大的麦穗的可能性。
▲数值模拟结果,横轴为 k,考察的所有选项个数;纵轴为 r,在最开始拒绝的选项的个数。颜色的深浅代表在这个参数下捡到最大的麦穗的可能性。可以看到,不同的参数选取会影响我们的最终结果
在图中可以看到,颜色最深的两个分别集中在中间,以及最右边的边界上。而这最右边的边界不是别的,正是我们的 1 / e 策略。因为如果我们取把选择的终点取到头的话,我们的回头草策略实际上看完了所有的选项。而且 N - k = 0,此时也失去了「吃回头草」的能力。
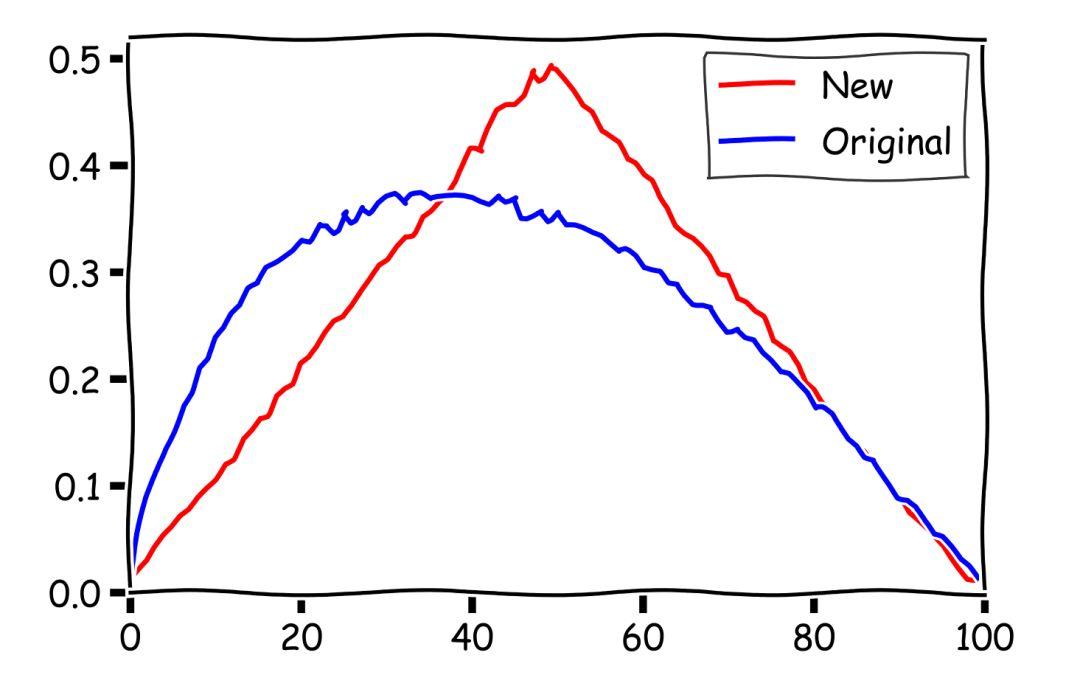
我们单独把对角线上的结果和最右边的结果拿出来进行比较。
▲数值模拟结果,横轴为数值模拟时选择的参数。图中蓝线代表原来的 1/e 策略,此时的横轴参数代表最开始拒绝的选项的个数。我们可以看到在 37 附近,蓝线确实取到了最大值。图中红线代表回头草策略,在 r = k = 50 的时候,我们可以以 50% 的概率取到最好的那个选择。此时对应的策略为只考察系统中一半的选择,然后回头选择之前看过的最好的那个
图中蓝线代表原来的 1 / e 策略,可以看到如果我们开始拒绝了 37% 的选择的话,蓝线确实取到了最大值 0.37。而图中红线代表吃回头草策略,直接在看完前一半的选项以后回头选择最好的,就能够以 50% 的概率取到整个队列中最好的那个。此时也确实发挥了吃回头草的极致……
光说这点好处肯定不能让你们坚定地选择吃回头草策略,接下来还有一些更猛的发现。
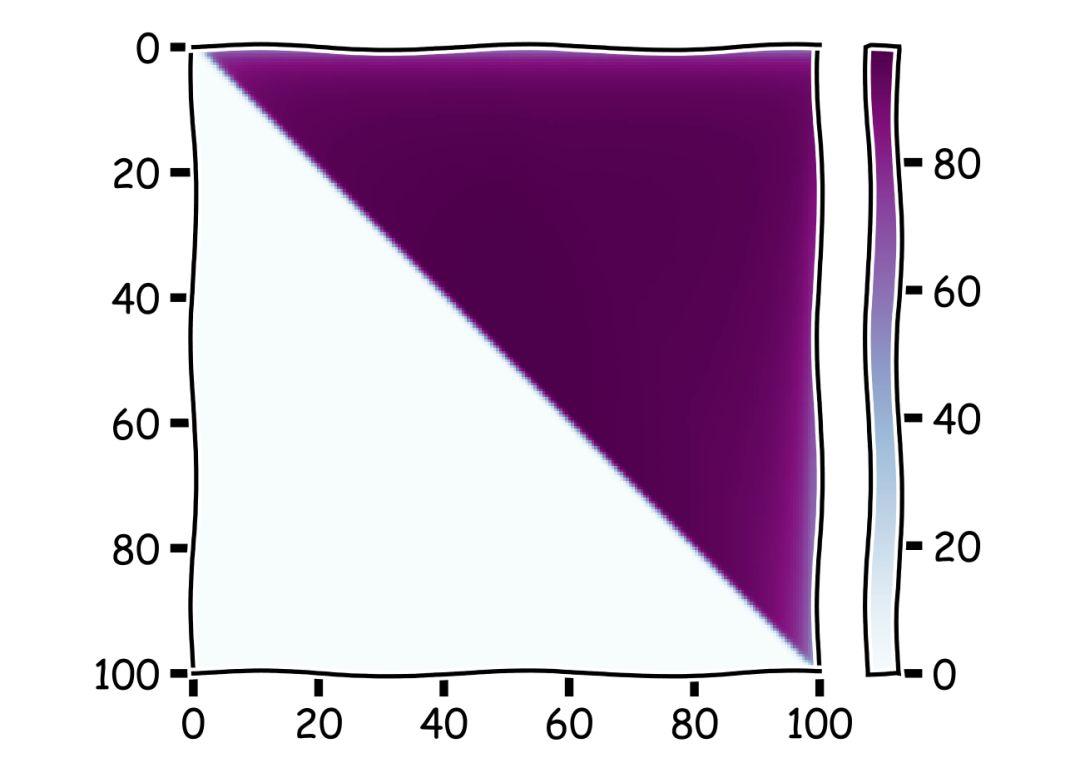
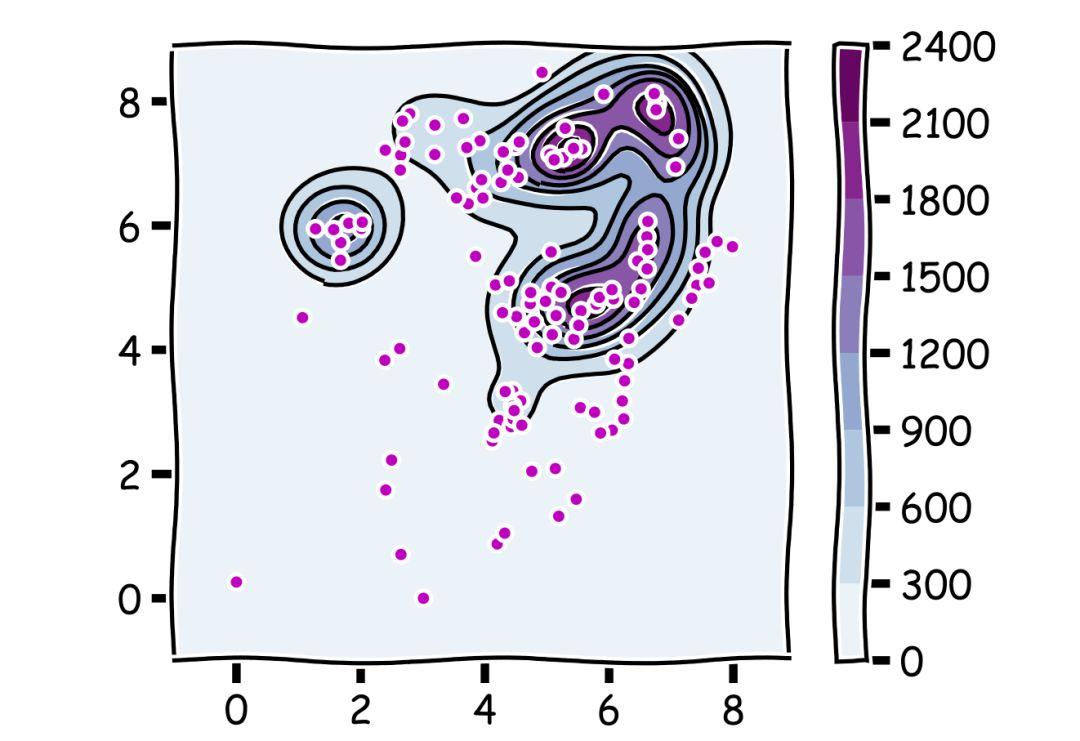
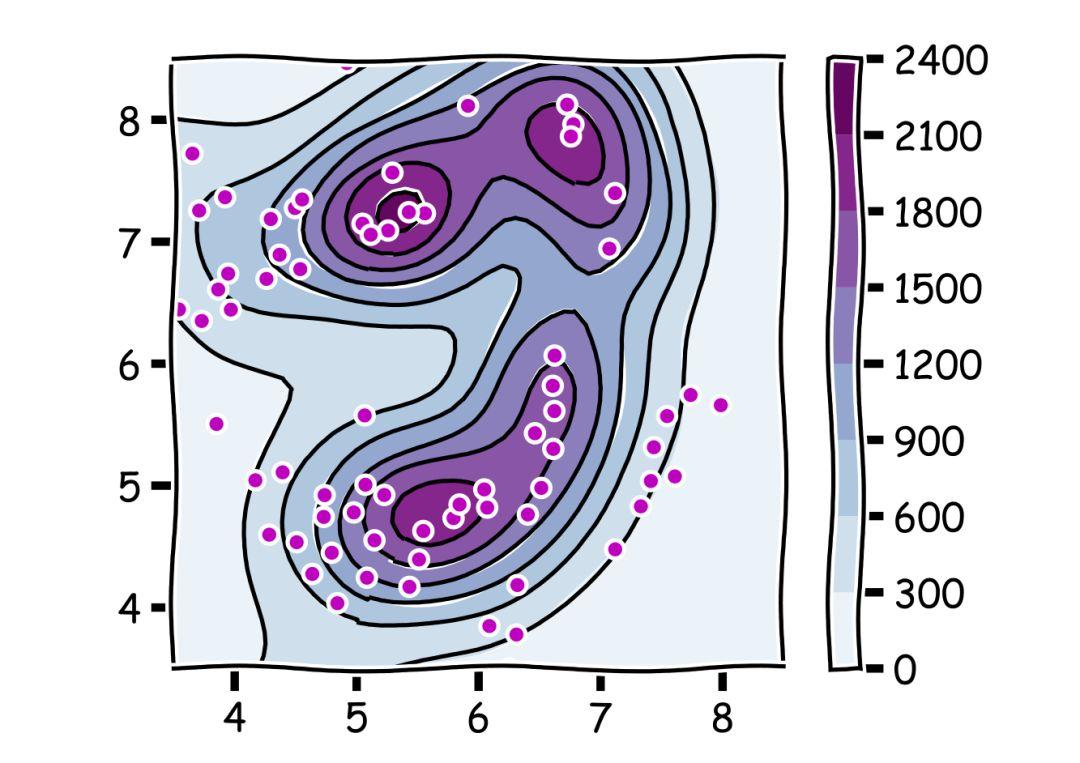
前面我们比较的是选中了最大的概率,但是我们并不只是想要最好的体验,我们还很关心下限。在找厕所的时候,我们平均的体验其实会更重要,比如比起一个稍微不那么干净的厕所,没有纸这一点显然更尴尬。所以我们接下来分析了 1 / e 策略和吃回头草策略中结果的均值。从下图看上去,大家好像都很优秀的样子……
▲颜色越深代表最后得到的结果中平均值越大
但是如果我们单独把 1 / e 策略和对角线上的吃回头草策略拿出来比较的话……
▲1 / e 策略和对角线上的回头草策略对比结果图
这是什么坑爹玩意啊?!?!1 / e 策略在这时候不仅不能取到平均结果的最大值,更是被吃回头草策略远远地落下了。 谁说好马不吃回头草?好马就要吃回头草! 5 理论结合实践

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡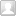 发表于 2025-3-12 17:58
发表于 2025-3-12 17:58














 提升卡
提升卡


