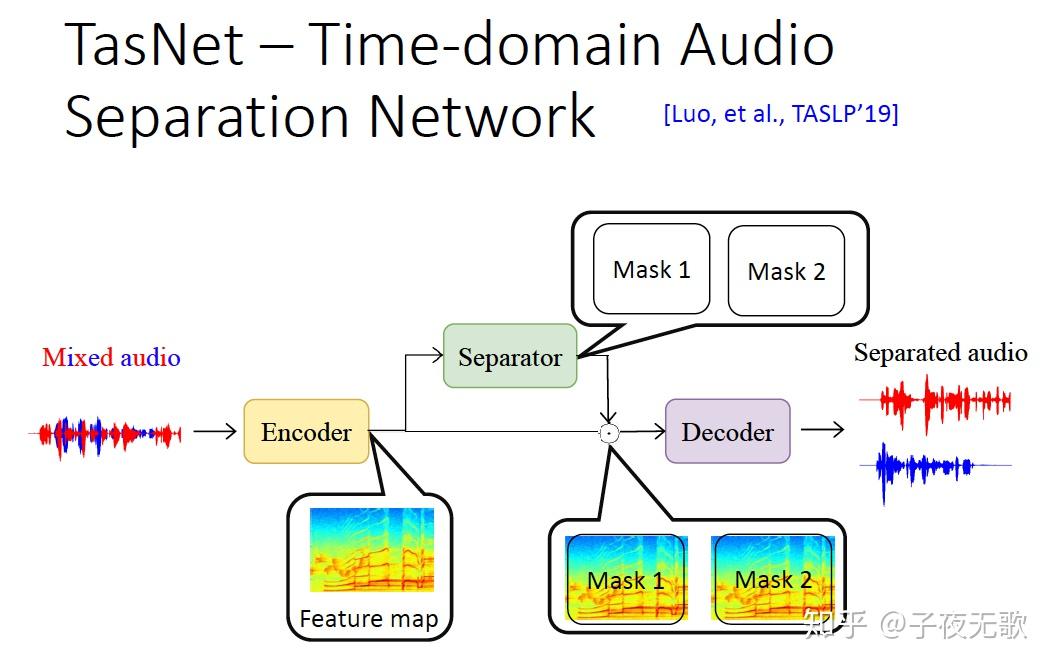
谷歌这篇文章《Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation》,宣称“攻克”了鸡尾酒会问题。从提供的视频演示来看,可以通过滑动控制只听某一个人说话,非常神奇。
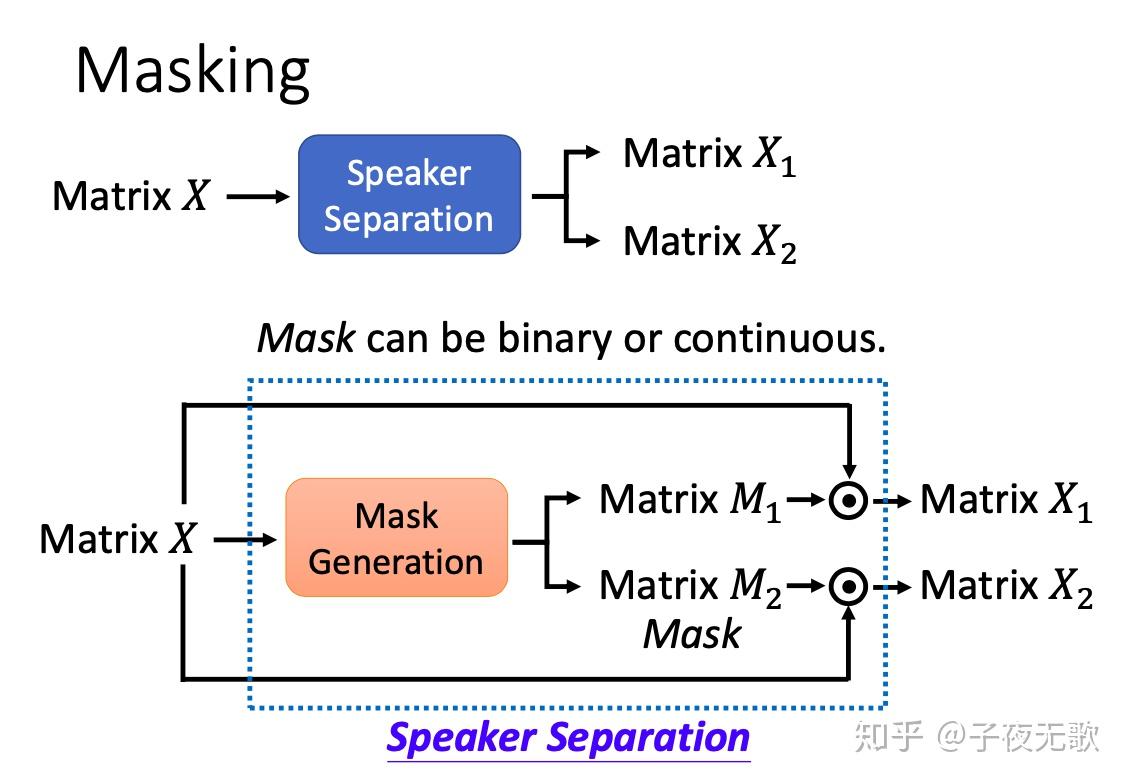
由于分离结果排列不确定,过去的深度学习方法通常只能做说话人相关的语音分离,即训练和测试的语音数据是相同的说话人的语音。Deep Clustering方法是最早应用于说话人无关的的模型,该模型训练的数据是这几个人的语音,测试数据可以是另外几个人的语音。
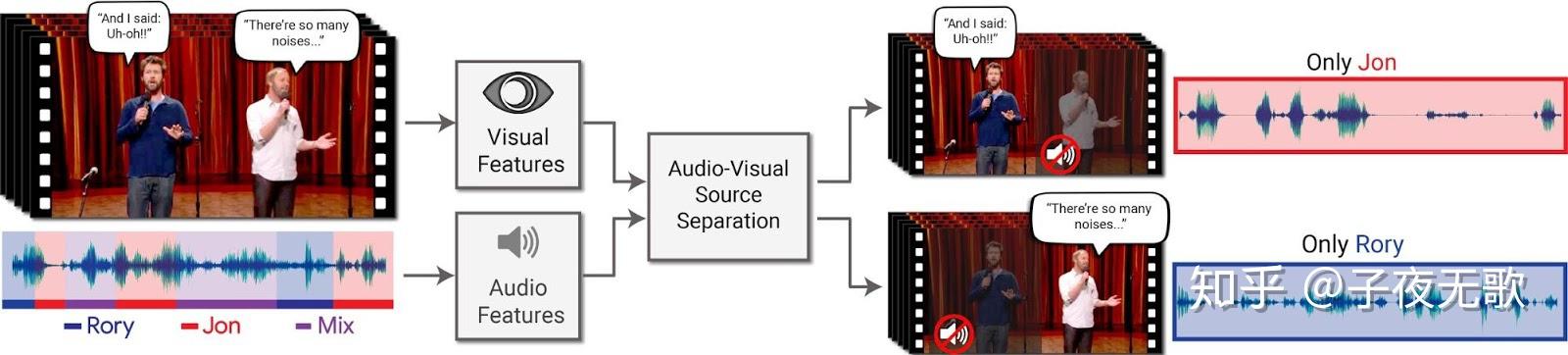
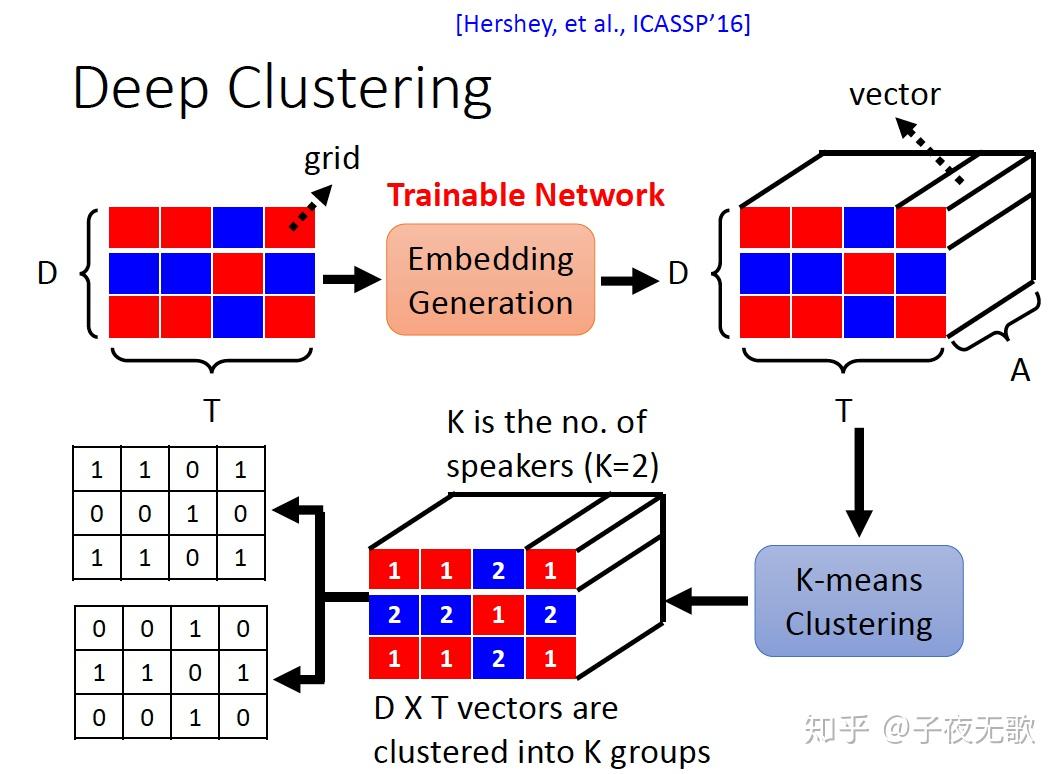
深度聚类Deep Clustering方法是MERL实验室Hershey等人于2016年提出的工作。Deep Clustering算法训练神经网络为输入特征中的每个元素生成一个具有区分性的嵌入向量(embedding),之后利用聚类算法,如K-means,对生产的embedding进行聚类,得出不同类别即是不同说话人的信号分离结果图。Deep Clustering性能和泛化性能(训练在英文,测试在中文等情况)都比较好,但缺点是它不是一个end to end的方法,因为聚类方法不能训练。
对于是时频域的语音信号,矩阵中的每个时频点只有一个元素,通过神经网络训练,对输入特征的每个时频点元素生产一个 D 维的embedding向量 V ,用以表示该时频点的说话人信息,对于所有的时频点,则得到embedding矩阵 \mathbf{V} \in \mathbb{R}^{N \times D} 。
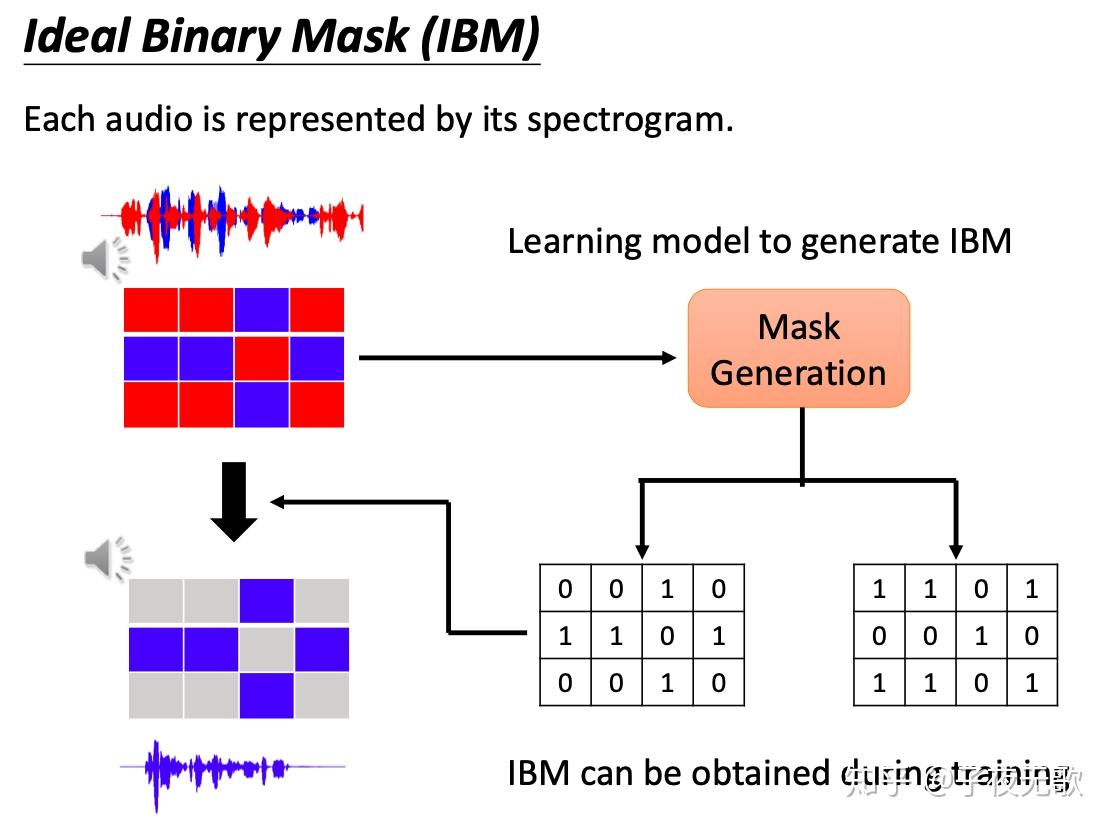
模型训练完成后,在测试阶段,输入混合语音的频谱特征,网络会对每个时频点生成embedding向量。然后把每个时频点的embedding向量看作一个样本,利用聚类方法,如K-means,对样本集合按照设定的类别 C 进行聚类,每一个类别对应一个说话人。测试阶段的聚类类别 C 可以与训练阶段不同,例如训练时有两个说话人,测试时可以使用3个说话人,网络同样是work的。有了分类之后,利用IBM时频掩蔽的方式从混合信号中提取每个说话人对应的语音信号。
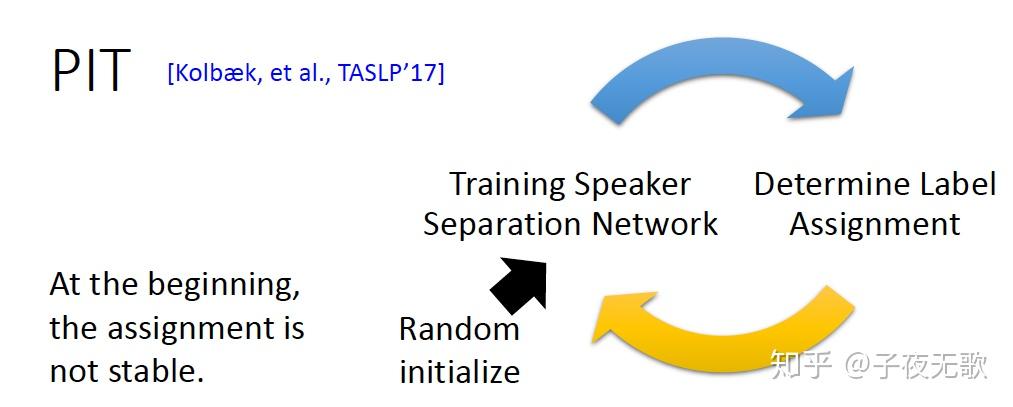
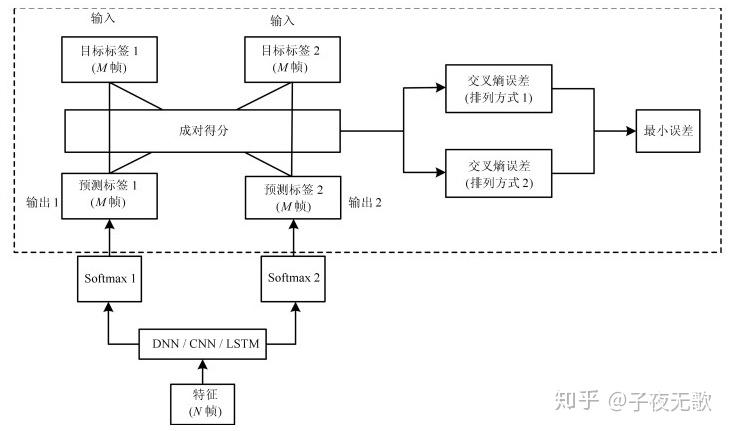
3.2 置换不变训练Permutation Invariant Train (PIT)
PIT 是腾讯余栋等人提出来的一种end to end的语音分离方法。PIT模型的设计思想是当模型给定,就可以给出一个确定的排列(选择可以使得损失函数最小的那一种排列方式),反之当排列给定可以训练模型,因此最初随机初始化一个分离模型,得到一个排列,接着更新模型,反复迭代至收敛。
假如有两个说话人 X_1 和 X_2 ,由于输出排列不确定,我们无法确定网络的哪一个输出与 X_1 对应,哪一个与 X_2 对应。假设网络对两个说话人的估计是$O_1$和$O_2$,说话人无关语音分离需要解决的问题就是 O_1 , O_2 与 X_1 , X_2 之间如何匹配的问题。PIT网络中对说话人语音的估计可以使用特征映射的方法,也可以使用时频掩蔽的方法。此时对说话人的预测可能由下式得到:
\begin{array}{l}\mathbf{O}_{1}=\mathbf{M a s k}_{1} \otimes \mathbf{Y} \\ \mathbf{O}_{2}=\mathbf{M a s k}_{2} \otimes \mathbf{Y}\end{array} \\
其中 \mathbf{M a s k}{1} 和 \mathbf{M a s k}{2} 分别是网络两个输出层的输出, \mathbf{Y} 是混合信号的时频表示, \otimes 表示元素相乘。对于 O_1 , O_2 与 X_1 , X_2 ,网络预测与真实目标之间可能共有两种组合方式,可以每种组合方式计算对应的预测误差,选择误差小的那种输出排列,利用这种排列再对网络进行训练。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 







 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年 2021庆中秋、迎国庆
2021庆中秋、迎国庆

 雷达卡
雷达卡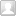 发表于 2025-3-12 14:55
发表于 2025-3-12 14:55








 提升卡
提升卡


