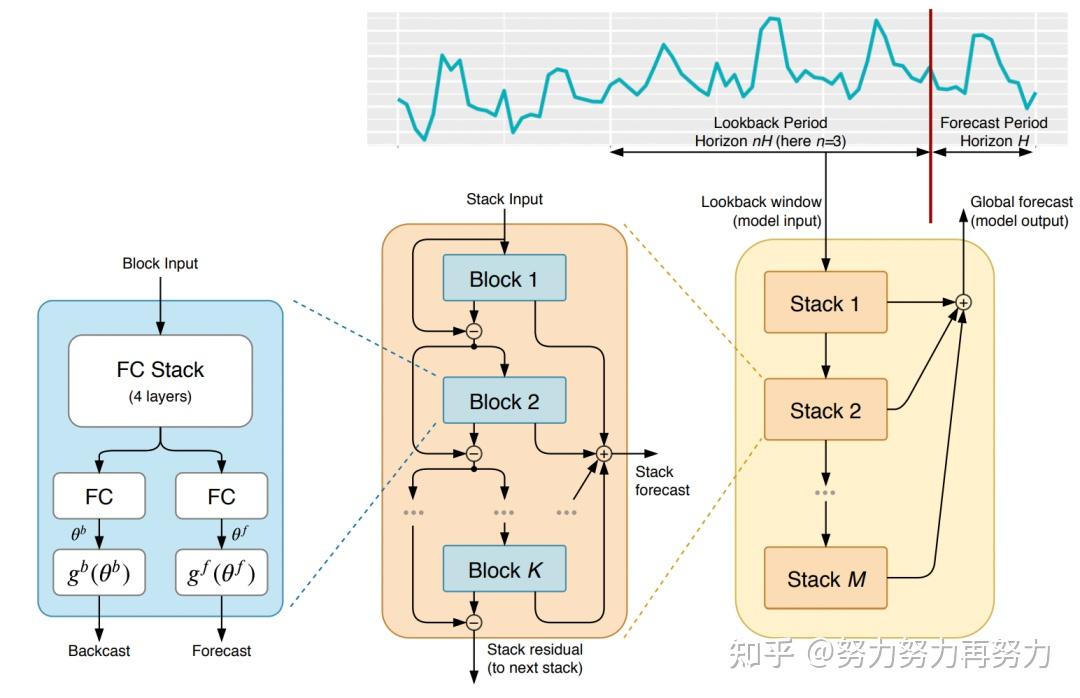
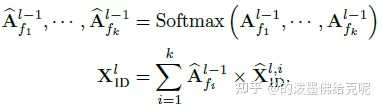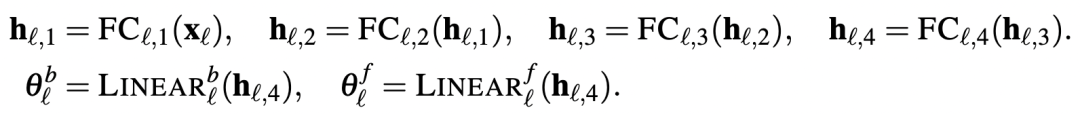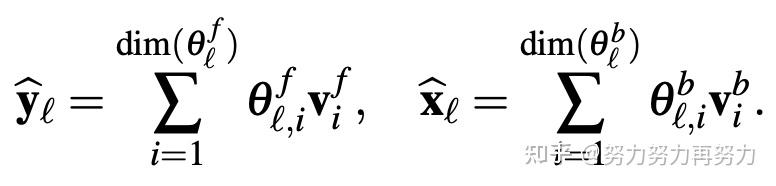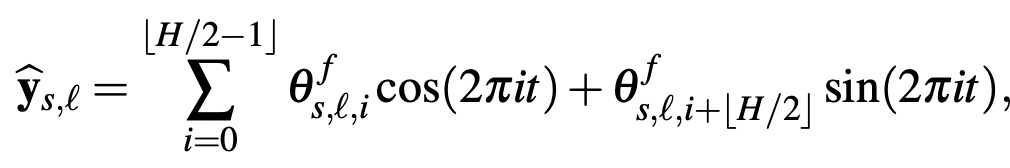金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
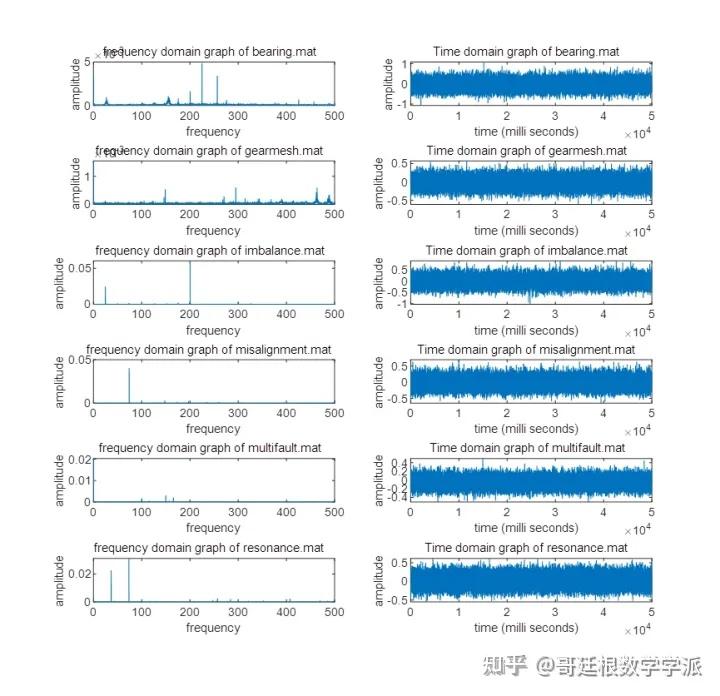
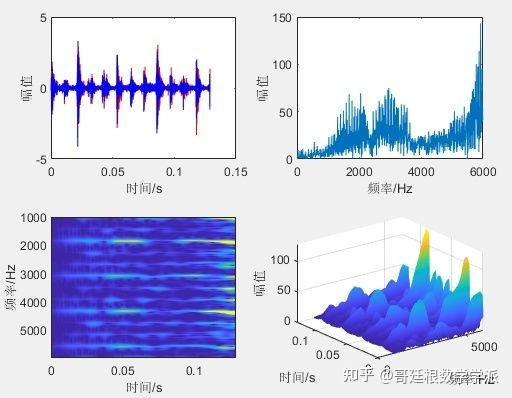
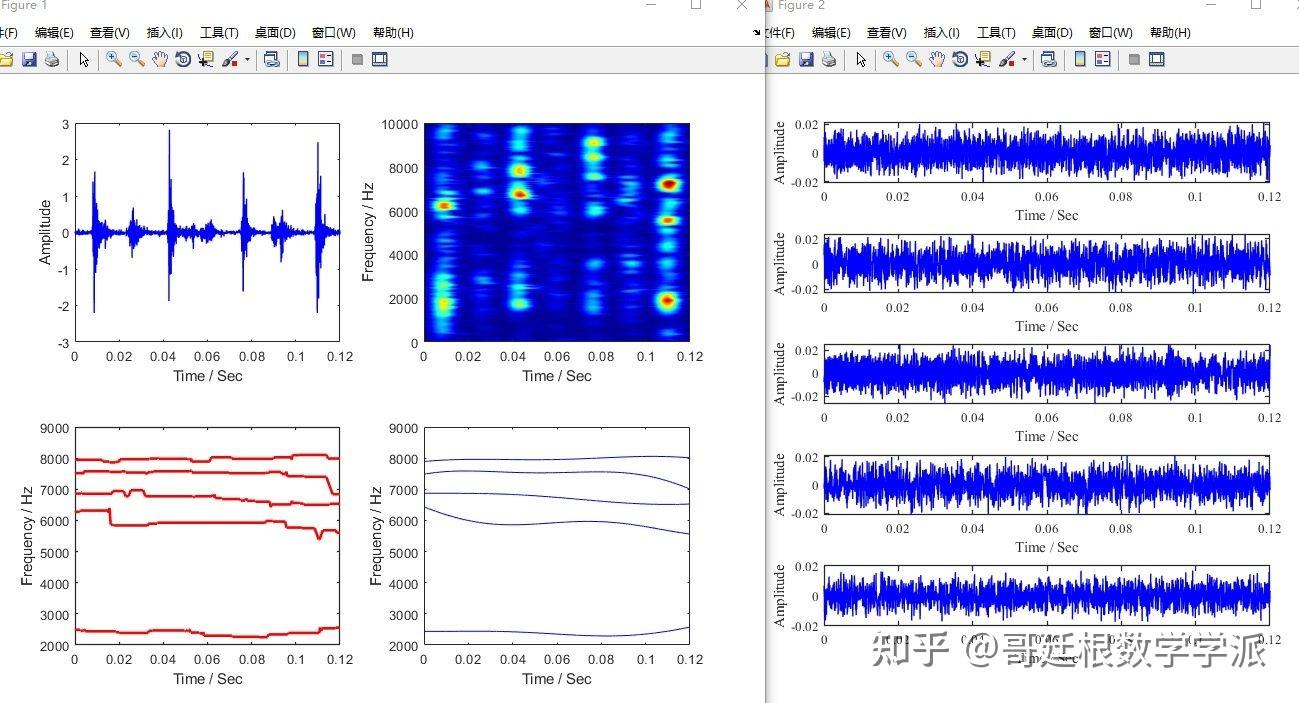
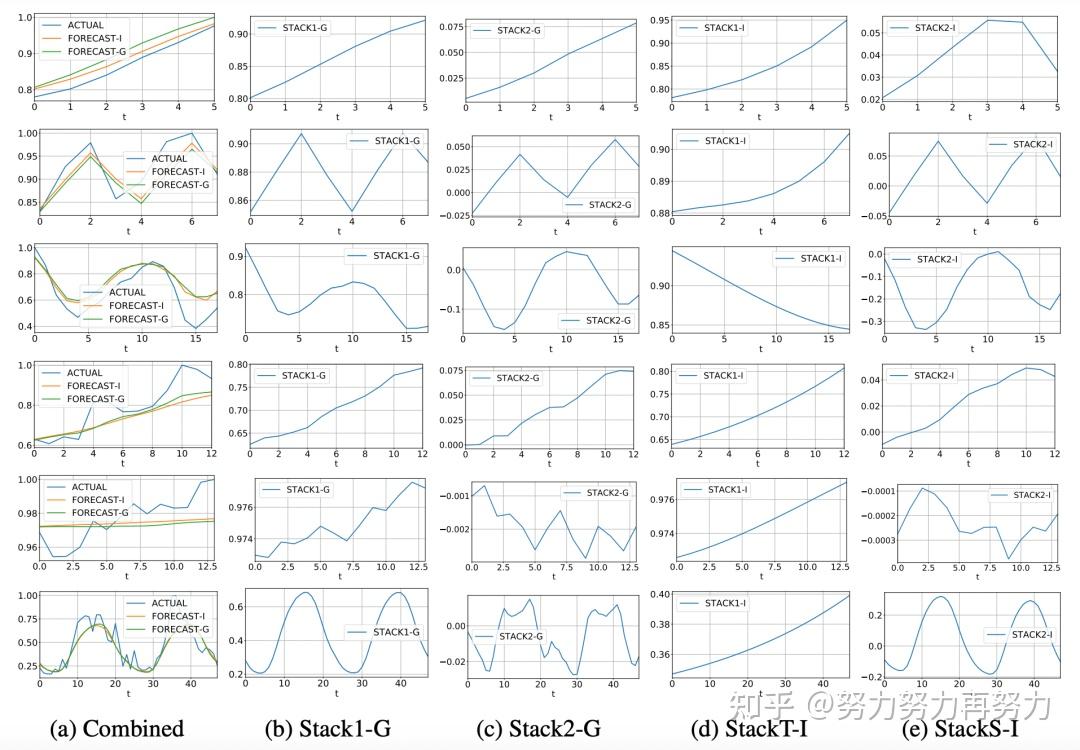
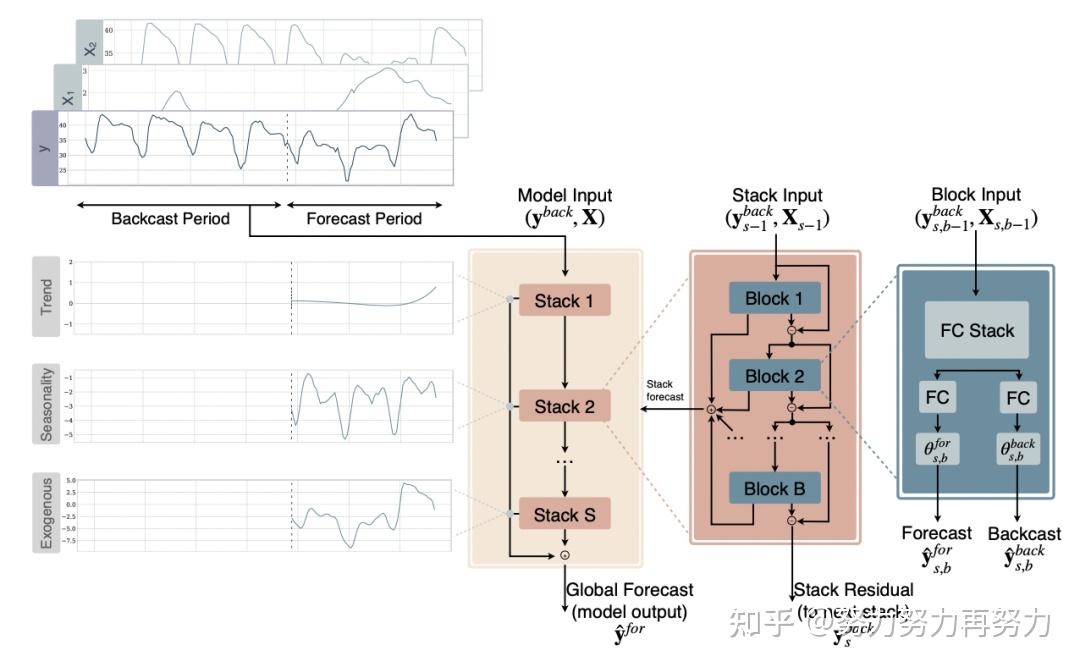
楼上有人提到频谱图,我弄一下
假设抽样频率为1000Hz,频谱图如下
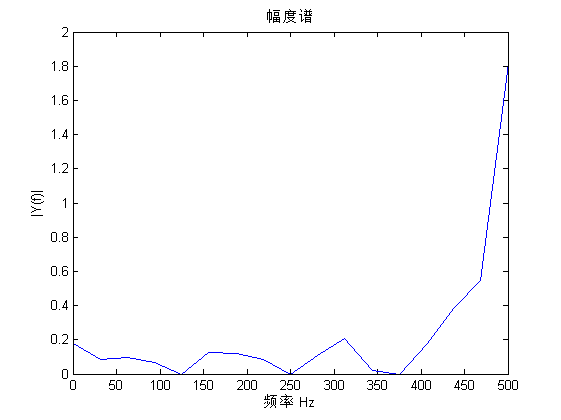
看出主要频率成分是500Hz,即以每两个数据为一个周期
matlab代码如下
Fs=1000;
tmp=[1, 11, 1, 10, 1, 12, 1, 11, 1, 10, 1, 12, 1, 11, 1, 10, 1, 12,1, 11, 1, 10, 1, 12];
tmp=2*(tmp-min(tmp))/(max(tmp)-min(tmp))-1;%归一化到[-1,1]
plot(tmp)
L=length(tmp);
NFFT=2^nextpow2(L);
Y=fft(tmp,NFFT)/L;
f=Fs/2*linspace(0,1,NFFT/2+1);
figure
plot(f,2*abs(Y(1:NFFT/2+1)));
title('幅度谱')
xlabel('频率 Hz');
ylabel('|Y(f)|')
|
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-12 14:13
发表于 2025-3-12 14:13


 提升卡
提升卡