用户名
UID
Email
密码
记住
立即注册
找回密码
只需一步,快速开始
微信扫一扫,快速登录
开启辅助访问
收藏本站
快捷导航
门户
Portal
社区
BBS
资讯
会议
市场
产品
问答
数据
专题
帮助
签到
每日签到
企业联盟
人才基地
独立实验室
产业园区
投资机构
检验科
招标动态
供给发布
同行交流
悬赏任务
共享资源
VIP资源
百科词条
互动话题
导读
动态
广播
淘贴
法规政策
市场营销
创业投资
会议信息
企业新闻
新品介绍
体系交流
注册交流
临床交流
同行交流
技术杂谈
检验杂谈
今日桔说
共享资源
VIP专区
企业联盟
投资机构
产业园区
业务合作
投稿通道
升级会员
联系我们
搜索
搜索
本版
文章
帖子
用户
小桔灯网
»
社区
›
C、IVD技术区
›
基因编辑技术
›
如何评价《Science》 公布的 2021 年度十大科学突破? ...
图文播报
2026庆【网站十三周
2025庆【网站十二周
2024庆中秋、迎国庆
2024庆【网站十一周
2023庆【网站十周年
2022庆【网站九周年
返回列表
查看:
8854
|
回复:
5
[分享]
如何评价《Science》 公布的 2021 年度十大科学突破?
[复制链接]
二维码
二维码
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:24
|
显示全部楼层
|
阅读模式
登陆有奖并可浏览互动!
您需要
登录
才可以下载或查看,没有账号?
立即注册
×
《科学》(
Science
)公布了2021年度十大科学突破,以 AlphaFold2 和 RoseTTAFold 为代表、基于 AI 的蛋白质结构预测获选。榜单还包括了其他 9 项重要科学突破。
《科学》公布2021年度十大科学突破--经济・科技--人民网
原文地址:https://www.zhihu.com/question/506670500
回复
使用道具
举报
提升卡
队长是我
队长是我
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:25
|
显示全部楼层
还是继续说下默克的这个药吧
2期结果:
在感染早期使用可以更快地清除人体内病毒,缩短有传染性的时间。
阿源老师:治疗新冠有药了?继国产药普克鲁胺后,又一个口服抗新冠药物获批
3期的中期分析:
与安慰剂相比,轻度或中度 COVID-19 患者的住院或死亡风险降低了约 50%。
如何评价默沙东新冠口服新药 Molnupiravir?
我都分析了,现在公布了最新的数据结果:
莫纳皮拉韦将住院或死亡风险从安慰剂组的9.7%(68/699)降低到莫纳皮拉韦组的6.8%(48/709),绝对风险降低3.0%,相对风险降低30%(相对风险0.70)。
还是那段话:
Molnupiravir是一款RNA聚合酶抑制剂,针对RNA病毒的广谱抗病毒药物,冠状病毒方面,它的前辈还有利巴韦林、瑞德西韦。这类药物把自己和RNA聚合酶结合,病毒RNA就结合不上去了,最后合成的就是假病毒,没有感染性。
一般情况下,广谱的抗病毒药物效果可能达不到某些朋友想象的那样,「吃下去就能很快见效,然后得到明显改善」,只能说在早期服用可以改善整体预后。
而且过于广谱的RNA聚合酶抑制剂还可能干扰人体细胞的运行。
回复
支持
反对
使用道具
举报
长长的路
长长的路
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:25
|
显示全部楼层
作为生物学逃兵,我看到这个“几乎全部是生物”榜单还是非常欣慰的。或许21世纪永远都不是生物学的世纪,但是生物学家们仍然在为人类开辟新的世界。尤其是人工智能预测蛋白质结构的重要性将在未来得到进一步拓展,我们有希望在未来看到一个更加现代、更加智能、更加高效的蛋白质解析与合成手段,这将帮助我们构建全新的药物与治疗体系,甚至能协助演化生物学家洞察生物演化的微观历程。我的一些同学正在这条道路上前行,在这里,我祝福他们能取得更进一步的成果。
<hr/>现在聊一下榜单的第二项——土壤古DNA。说实话,我很吃惊,虽然这个榜单本身不具有排名的意味,但是古生物相关的研究被列在开头我还是非常惊喜的。相比于其他的突破,土壤古DNA更像是一个新的研究方向的成型——它是由许许多多工作一道构成的全新领域,因此,不会出现一个石破天惊的大新闻,大家对于这个方面会更为陌生。我会在下文中简单介绍一下这个研究领域,并向大家说明为何它能被列入2021年的年度科学突破。
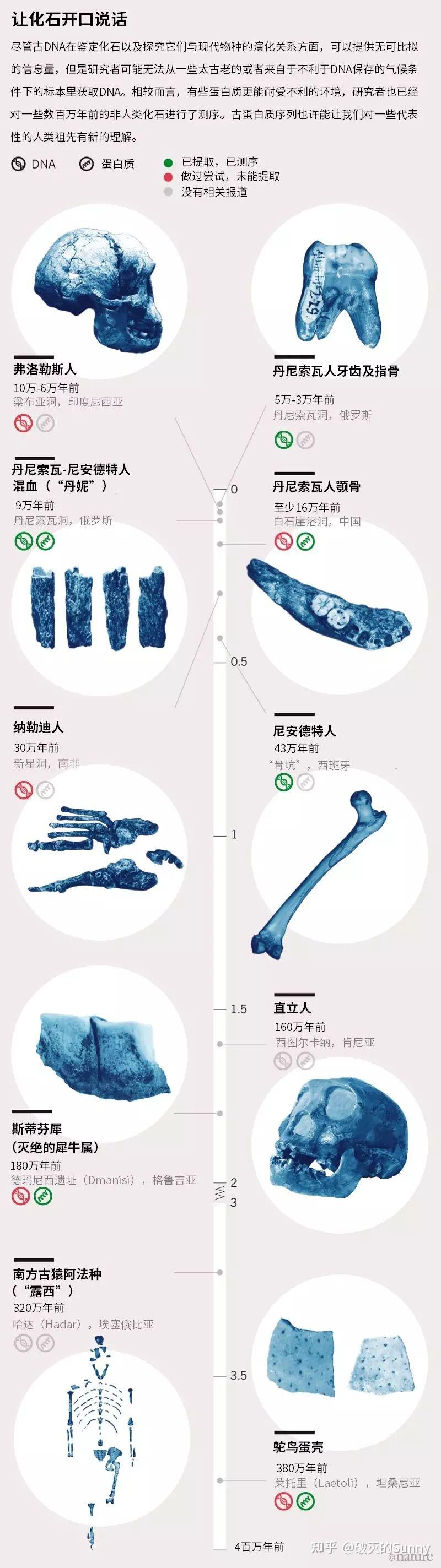
说到古DNA研究,大家可能会想到《侏罗纪公园》用蚊子血复活恐龙的桥段——这也算老生常谈了——实际上的古DNA 研究,基本都是建立在生物体遗骸之上的。简单来说,通常情况下,研究人员是用骨骼作为材料提取古DNA。我们将具有研究价值的材料磨碎,然后按照提取流程去捕获那些残余的古DNA。因为生物体生活的年代离我们相当遥远,经过漫长的降解、成岩过程,我们基本不可能得到生物体完整的序列信息,因此很多时候在这些骸骨里我们只能找到一些零散破碎的DNA 片段。我们拼凑起这些碎片,建立基因文库,再与现生物种与其他文库的序列进行对比,识别出标志性片段,最后用这些有限的材料完成生态学与生物演化研究。
可以说,古DNA 研究的最关键部分就在于材料的保存水平——只有良好的保存才能提供有效的信息。
因此,古DNA研究长期处于一个非常尴尬的状态,一方面它能讲述的故事是古生物学中最坚实可靠的,大家都重视它的结果;但另一方面,古DNA材料实在是太难以获得了,好的材料实在是可遇不可求,虽然我们不断更新技术,设计引物,力求提高古DNA的捕获率,但是相较于形态学研究要求还是太高了——
假如我们要研究某个类群的迁徙与演化,却只能在零星的材料中发现古DNA 信息,这显然是缺乏说服力的。
目前人类材料中的古代大分子的保存情况,引自Nature Portfolio,侵删
因此在古DNA之外,一些研究人员开始尝试使用古蛋白质或者古脂质等材料作为研究对象,用以补充古DNA研究的不足。但是这些研究都面临着相同的问题:
假如化石材料里面没有相关分子的保存该怎么办?假如这些材料被污染破坏到无法识别该怎么办?
虽然转换研究对象是一个行之有效的方法,但是假如还是依赖于化石本身,那么在本质上还是一个摸奖的过程——做不做的出来研究,还是得凭自己的欧气。
该怎么办呢?这时候,一个新的领域进入了古生物研究,也就是今天的主角——土壤古DNA,当然,有些学者更愿意称其为
古环境DNA(Ancient Environmental DNA,ancient eDNA),
也就是那些散落于环境中的古DNA。
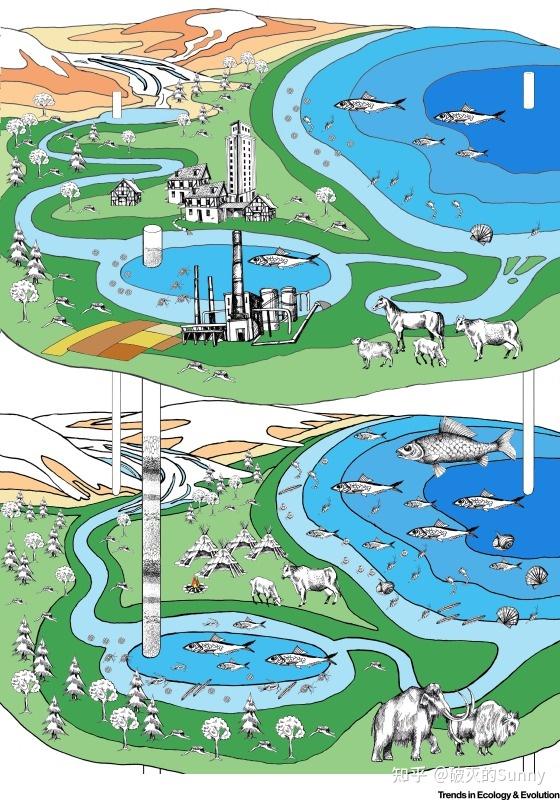
虽然大家对于DNA 都有着一些认识,但是可能很难想象这个东西其实在我们的生活中无处不在——没错,字面意义的无处不在。不仅仅在生物体身上,生物体生活的环境中,到处都能找到散落的DNA 碎片:土壤、水体,甚至空气——就在今年3月,伦敦玛丽皇后大学的研究人员就在饲养裸鼹鼠的房间内的空气中找到了裸鼹鼠和人类的DNA[1]。这些脱离于生物体本身,游离于环境中的eDNA 是生态学研究的重要材料。从1987年首次提出这一概念后,便吸引了许多人的目光[2]。但早期的研究主要是围绕着土壤微生物的研究,这是由于其占比的绝对优势造成的。不过,随着高通量测序技术的发展,那些低含量甚至痕量的DNA 分子也能够从原始材料中被筛选出来,这便扩展了eDNA 的适用范围,很快,生态学研究者便开始使用这一技术进行物种的检测。通过采集水体与土壤中的eDNA,生物学家们便能够在完全缺失生物体本身的情况下研究其生活范围与活动轨迹。一些濒危物种或入侵物种的检测就会采用这一技术,比如斑鳖[3]、江豚[4]、鰕虎鱼[5]或者大家没听说过的襀翅目小昆虫[6]。
eDNA中包含了不同时间段的生态信息,可以用于复原生物演化与环境的更替
eDNA 的蓬勃发展很自然地吸引到了古生物学家,尤其是最近几年eDNA 应用于大动物之后,古生物学家看到了这一领域在古生物研究中大放光彩的可能。虽然从沉积物中筛出古DNA的难度相当大,但相较于无头苍蝇一样地去撞特异保存的化石材料来说,还是相当可观的。一开始的研究主要围绕着湖泊沉积物,研究的年限也相对较近,主要材料也是细菌与真核藻类。但很快,研究人员发现了洞穴沉积物以及线粒体DNA的潜力。
洞穴沉积物的优势在于其环境相对稳定,相较于暴露环境,更容易保存大动物尤其是人类的DNA信息;而线粒体DNA 的优势则在于其多拷贝的特点,一个细胞只能有一个核基因组,但是线粒体却成千上万。
这样一来,筛选得到遗失在环境中的古线粒体DNA 材料成为了古人类学家的重要方向。只需要找到这小小的一段DNA,就可以在缺失化石材料的不利状况下作出漂亮的论断。说到这个就不得不提到去年轰动一时的文章:在甘肃夏河县白石崖溶洞的洞穴沉积物中发现了丹尼索瓦人的线粒体DNA,这一发现可以说是沉积物线粒体古DNA研究的代表性成果[7]。
而今年的研究却更加鼓舞人心——因为,我们的研究开始转向了核DNA。在之前我提到,核DNA的保存难度更高,但它们也包含了更为丰富的遗传信息。一般的线粒体DNA
只有16500 个
碱基对,但是核DNA则有
数十亿
个碱基对,这样巨大的差异使得二者携带信息的量级完全不可同日而语。今年5月,马克斯·普朗克研究所的一个研究团队报道,在利用分子探针勾选后,他们发现了第一个来自沉积物的人类的核DNA[8]。
这让我们有机会用极其精细的方式去研究不同人种在时空中的变化与交流,并且核DNA 摆脱了线粒体DNA母系遗传的限制,使得古DNA的研究进入了全新的阶段。
在西班牙挖掘Estatuas洞穴的研究人员们
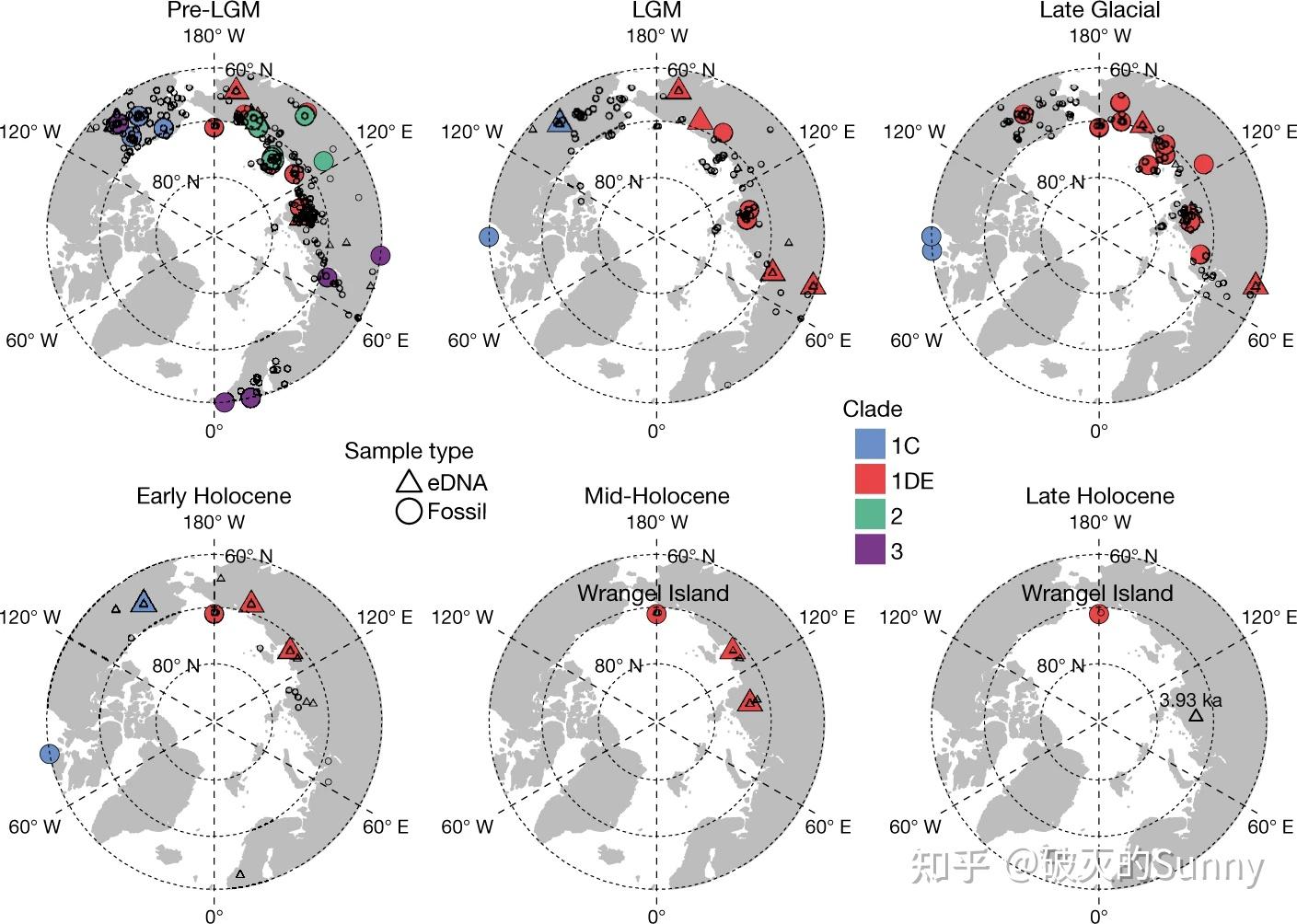
随后,维也纳大学的研究团队在佐治亚州的西部的Satsurblia 洞穴中使用了分子探针,他们在那里发现了古代工具与动物化石,并利用eDNA 识别到了之前未被发现的一个生活与2.5万年前的尼安德特人系[9]。而在洞穴之外,冻土中eDNA 的研究也进入了一个高潮,eDNA 与化石DNA 的协同使用极大地促进了猛犸象类群的分析。借助eDNA 提供的更宏观的视角,我们得以勾勒出一个明星物种的演化与衰落的图景。今年10月,剑桥大学的一个小组利用eDNA 描绘了猛犸的灭绝因素[10]。在这张图上,我们可以看出eDNA 的应用解除了化石材料的诸多限制,更加真实地表现了灭绝生物的生存范围的变化。
不过有趣的是,这个文章的结果确很快遇到了反驳——不过与eDNA 没有关系
古DNA的研究,一直是古生物研究中备受瞩目的领域——并不仅仅是因为《侏罗纪公园》带来的公众关注,更重要的是,这是我们揭开时间的重重面纱,去直视那些古老生命最可靠直接的方式。对于每一个古生物的研究者来说,古DNA 都是充满魅力与挑战的,它能够告诉我们那些本不会与我们发生关联的历史的真相,与此同时,它也截取了一个片段,让处于现在的我们有机会去与自己的历史发生真实的关联。
在古DNA 的魔力之下,那些被许许多多因素所束缚的历史才突然显现,并向我们证明,在这颗星球上,我们本是一体。
我们总是好奇我们从哪里来,在环境古DNA 的协助下,我们得以回忆起更多的往昔。
回复
支持
反对
使用道具
举报
继续前进
继续前进
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:26
|
显示全部楼层
NIF 打出 1.3MJ 确实是巨大突破,比之前的能量释放直接高了一个量级。不过激光聚变作为能源而不是物理研究的话进度是远不如磁约束的。主要是因为从能量输入激光器直到弹丸吸收激光这整个过程中堪称悲剧的能量转化率,NIF 一次放电的能量输入应该差不多 200MJ,折算一下 Q 值连 0.01 都没有。
当然在物理上激光等离子体领域还有很多东西不清楚,这里的条件实在过于极端(高温、强场、高密度),而且和磁约束不一样的是它不存在稳态,所以实验测量要麻烦很多。随着对激光等离子体相互作用的理解不断深入,这一数字肯定还有非常大的提升潜力。
磁约束的话,今年的主要新闻可能就是 MIT 展示了他们的高温超导,据说真的可以做出来 20T 的磁场强度;以及 JET 时隔二十几年终于重启了氘氚放电。不过强场在大装置上的效果要等到 SPARC 真的建起来之后才能得到验证,JET 今年氘氚放电的结果也还没发出来。虽然肯定都是一些值得乐观的结果,但在点火一级的装置真的给出足够好的结果之前,还是保持谨慎乐观更稳妥一些。
回复
支持
反对
使用道具
举报
同花顺
同花顺
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:27
|
显示全部楼层
讲下2021年十大科学突破中的:
CRISPR基因编辑上临床
。
包括两个基因编辑成体疗法,一个是
治疗眼科疾病的Edit-101
,2021年出部分临床1期结果,数据比较嘤嘤嘤;另一个是
治疗肝脏疾病的NTLA-2001
,2021年也出了部分临床1期结果,数据很不错。
具体来讲一下(内容复杂,可以只看粗体结论):
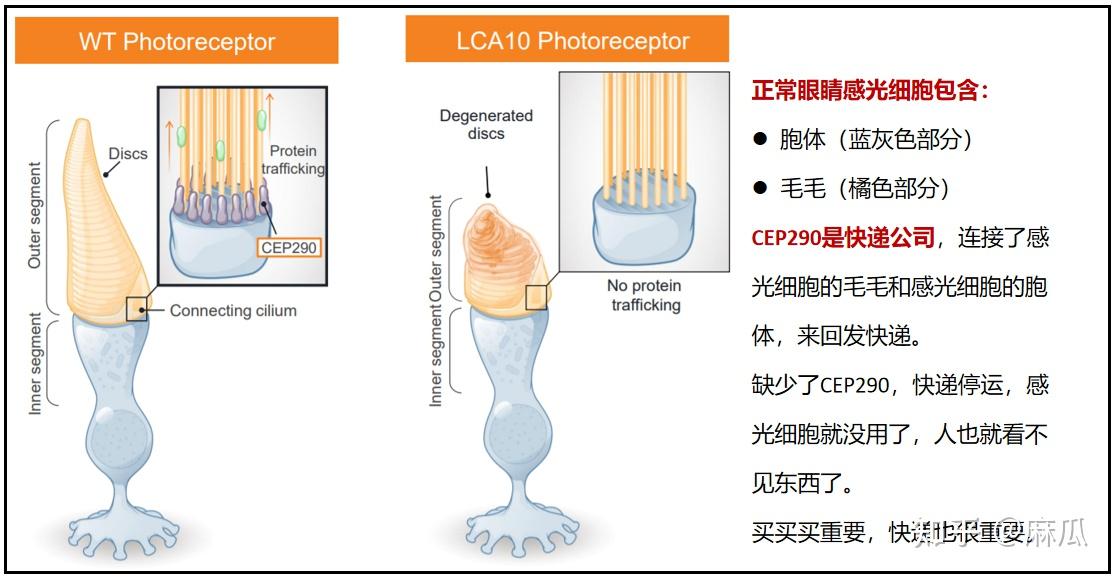
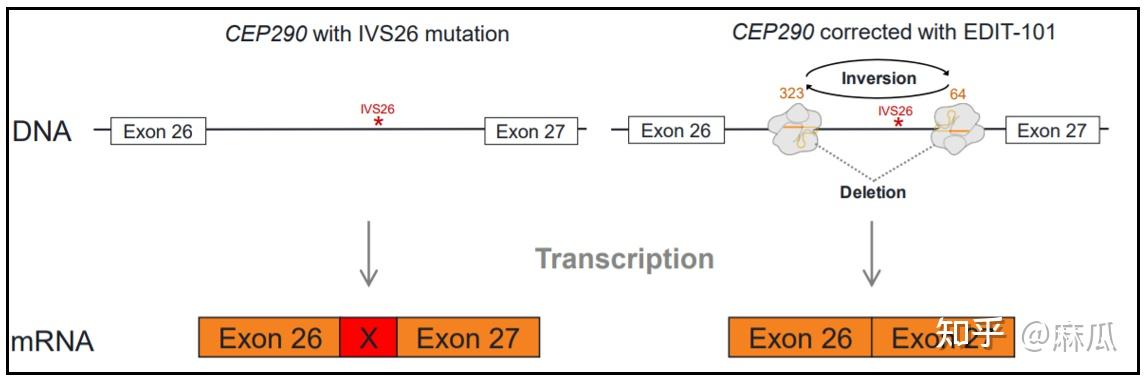
1. Edit-101,第一个基因编辑成体治疗,来自于Editas公司,基因编辑靶点Cep290,治疗眼科疾病先天性黑矇症10
:
先天性黑矇症10(LCA10)疾病原理:
这个疾病是因为眼睛感光细胞的Cep290基因突变,导致CEP290蛋白缺失。
你可以把CEP290看作是个快递公司,连接了感光细胞的毛毛,和感光细胞的胞体。缺少了快递公司,感光细胞缺乏生活的动力,就此躺平,人也就看不见东西了。
Edit-101基因编辑疗法原理:
Edit101这个基因编辑疗法具体针对的是IVS26这种突变类型的Cep290。
IVS26是Cep290内含子里一个突变,突变后影响可变剪接,影响了CEP290全长蛋白表达。那怎么办呢?把IVS26周边区域整个切掉就完事了。
具体来说,就是通过AAV(一种病毒)把基因编辑工具Cas9和两个sgRNA递送到眼睛里,这些工具切掉眼睛感光细胞里基因Cep290的突变区域,从而恢复Cep290表达。
Edit-101的动物实验IND结果还不错,没看到明显毒性:
2020年,Editas公司在Nat Medicine上刊登了Edit-101动物实验IND的结果。数据显示,Cep290基因在眼睛里的编辑效率不错,CEP290蛋白在感光细胞表达了,整体疗法也没什么能检测到的毒性。
但LCA10这个眼科疾病有个大坑,没有能模拟人类疾病表型的小鼠模型。没法知道恢复CEP290表达后,究竟让多少感光细胞看到光,无法准确衡量药效。具体效果只能看病人用了以后怎么样。
随后,Edit-101上了人。
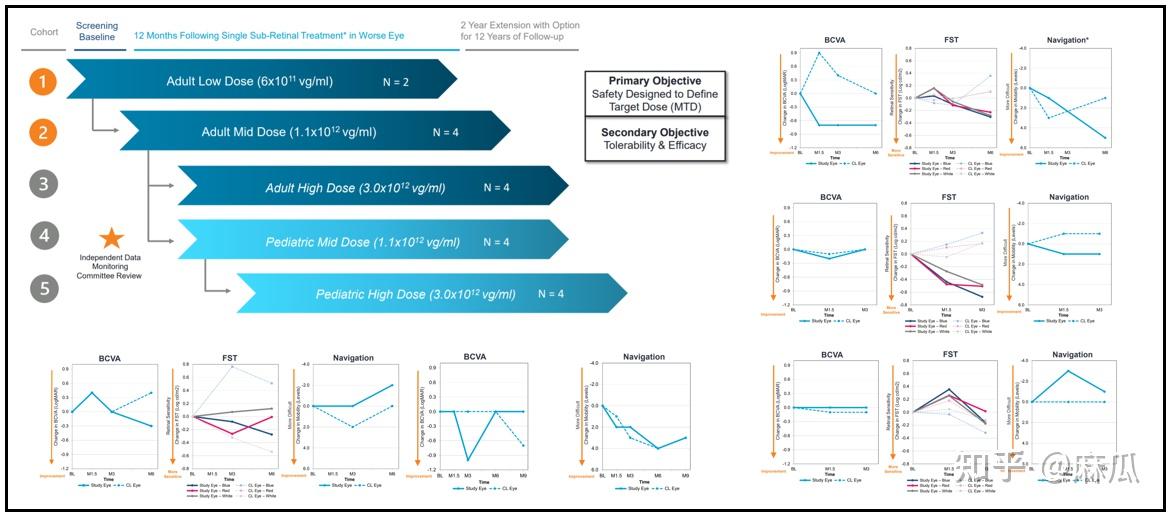
Edit-101的临床1期结果比较差,药效不强:
2021年Editas公布了Edit-101的部分临床1期结果,低剂量组两个病人,无效;中剂量组三个病人中有两个病人能看到一定效果,效果也是乱七八糟。有一个病人一个多月还有效,三个月就没效了,目前把这个病人算作那两个有一定效果的病人(蜜汁微笑)。
至于最终Edit-101临床1期表现如何,还要等高剂量组结果,药效结果估计很悬。
只能说,Edit-101是第一个CRISPR/Cas的成体基因编辑疗法,是一次不错的尝试。
<hr/>
2.第二个CRISPR/Cas的基因编辑临床NTLA-2001,来源于Intellia公司,基因编辑靶点Ttr,治疗肝脏疾病转甲状腺素淀粉样变性(ATTR)。
转甲状腺素淀粉样变性(ATTR)疾病原理:
TTR是转甲状腺素蛋白,病人的TTR蛋白折叠错误或表达过量,淀粉样变性沉积在全身,导致发病。主要症状是心衰,突变的TTR蛋白沉积在心脏,一般发现时是50-60岁,心衰5年左右,人就不行了。另外,突变的TTR沉积在神经系统,也容易产生多发性神经病变。
NTLA-2001基因编辑疗法原理:
NTLA-2001原理很简单,TTR不好,那就把这个基因敲掉。之前另一个公司Alnylam做过siRNA敲低。只不过Intellia通过基因编辑敲除Ttr,敲得更干净。
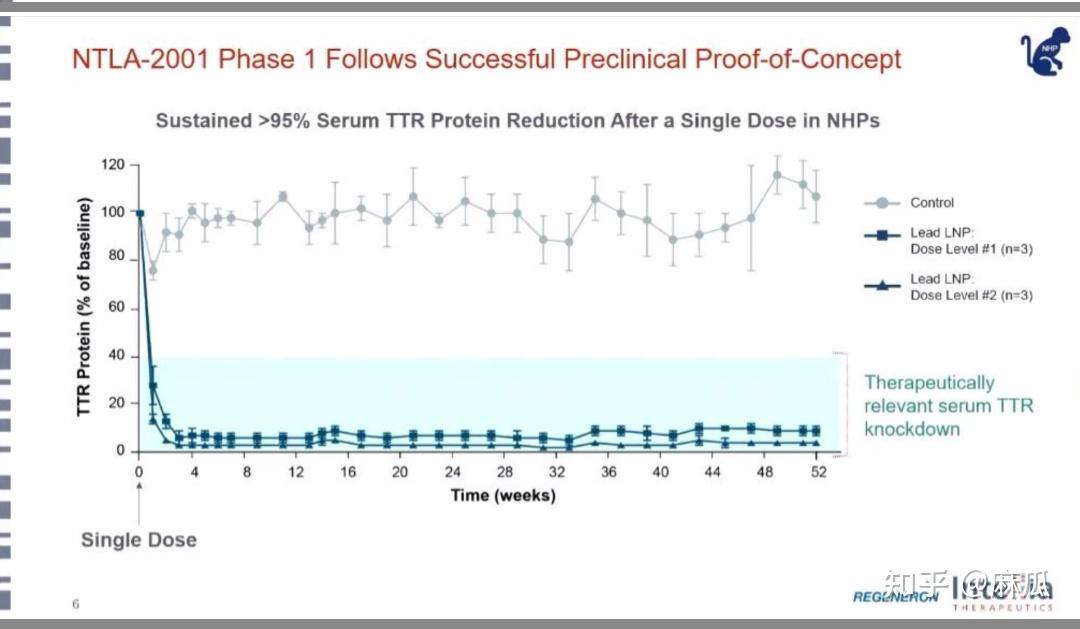
NTLA-2001的动物实验结果还不错,又安全又有效。
先讲安全性。
NTLA-2001有个重要特点:用纳米脂质体包裹Cas9 mRNA和sgRNA,进入细胞瞬时表达出Cas9进行切割。
Intellia通过脂质体纳米颗粒递送CRISPR/Cas,进行成体细胞的DNA基因编辑(图片来源:2021 ASGCT)
瞬时表达,减少Cas9蛋白在细胞存在时间,有两个好处:
1.基因毒性更小:瞬时表达的Cas9蛋白不会持续切割,降低了Cas9脱靶风险。
2.免疫原性更低:Cas9蛋白存在的时间短,引发免疫反应概率低。
再讲有效性。
NTLA-2001把TTR蛋白敲低到10%以下。
上面灰色的是没用药时猴子的TTR蛋白,很高。 下面绿色的是用药敲掉TTR,TTR蛋白表达极低。
TTR敲低,是不是一定能治疗ATTR这个疾病?
很早之前Alnylam公司已经证明通过敲低TTR,可治疗TTR变性引起的周围多发性神经疾病。连对应siRNA药物Alnylam的Onpattro (Patisiran)都已经在2018年上市了。
Intellia的CRISPR/Cas比siRNA强,药效上没什么问题。
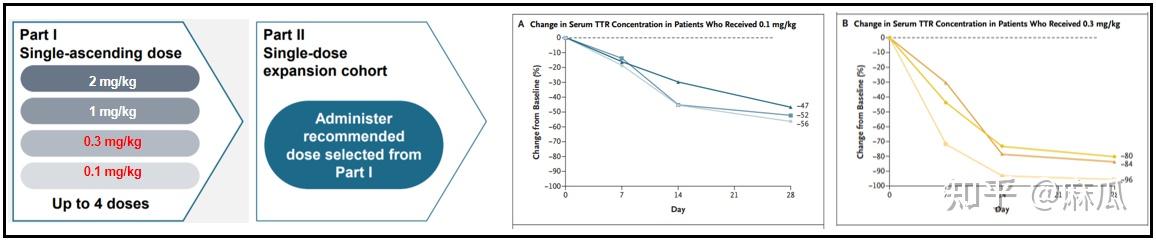
NTLA-2001一期临床,目前公布的药效指标还不错:
目前NTLA-2001一起临床低剂量的两组病人结果已经出来了,看样子TTR蛋白降得非常低,基本0.3mg/kg这个剂量就没太大问题。
TTR蛋白敲低就有药效,这是之前临床证实过的。NTLA-2001这个临床实验,药效上很稳。
<hr/>
总结:
2021年一项重大科研进展是CRISPR上临床,主要指Edit-101和NTLA-2001这两个基因编辑管线出临床结果。
很遗憾,很多人可能意识不到现代生物医药行业正在发生哪些重大变化。
很多人对药物的观念还停留在小分子药物上。有些人可能已经在生活中见到过抗体药。而医药公司已经在开发核酸药物,甚至有核酸药物已经上市了。
在大家不熟悉的地方,有很多悄摸摸的进步。
科技的力量。
回复
支持
反对
使用道具
举报
长长的路
长长的路
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2025-3-11 14:27
|
显示全部楼层
Science发布2021十大科学突破,AlphaFold居榜首!
来源:
中国生物技术网
近日,Science 杂志公布了 2021 年的年度科学突破榜单,AlphaFold 和 RoseTTA-fold 两种基于人工智能预测蛋白质结构的技术位列榜首。
除此之外,年度科学突破还包括:开发针对 COVID-19 的抗病毒药、μ 子的新测量、火星地震观测、从土壤恢复古代人类 DNA、CRISPR 体内应用、对早期人类发展的新见解、使用迷幻类药物治疗 PTSD、开发用于治疗传染病的单克隆抗体以及聚变能生成的进步。
此外,Science 杂志还评选了三个年度科学故障(breakdowns),包括实现气候目标的希望渺茫、阿尔茨海默病药物引发愤怒,以及科学家们因新冠疫情受到排斥和攻击。
本文主要介绍本年度最重要的科学突破——基于人工智能的蛋白质结构预测。
结构生物学持续 50 多年的困惑
我们都知道,蛋白质是生命活动的主要承担者,甚至毫不夸张的说,没有蛋白质就没有生命。因此,长期以来蛋白质都是生命科学工作者研究的重点。而其中,蛋白质的结构更是众多生命科学工作者研究的热点,毕竟其主要功能是由结构决定的。
1957 年,John C. Kendrew 和 Max F. Perutz 通过 X 射线晶体学确定了第一个蛋白质结构。不久之后,Christian B. Anfinsen Jr. 提出蛋白质的结构在热力学上是稳定的,似乎可以根据蛋白质的氨基酸序列来预测蛋白质的三维结构。
然而,蛋白质的结构复杂性远超人们的想象。依据中心法则,蛋白质主要是由 DNA 转录成 RNA,再翻译成肽链后组装而来,一个蛋白质分子是由一条或几条多肽链组成,多肽链则折叠成特有的形状。同时,蛋白质分子的专一形状是由4个层次的结构决定的,包括一级、二级、三级和四级结构,前一级结构决定后一级结构。
其中多肽链的氨基酸序列是一级结构,一级结构中的部分肽链卷曲或折叠产生二级结构。二级结构经过一系列的构象改变形成三维结构即三级结构,一般为球状或纤维状。三级结构有特定的结构域,形成结合位点或调节位点,可以结合特定结构的物质,行使特定的功能。两条或两条以上的多肽链组成的蛋白质,可以形成四级结构。
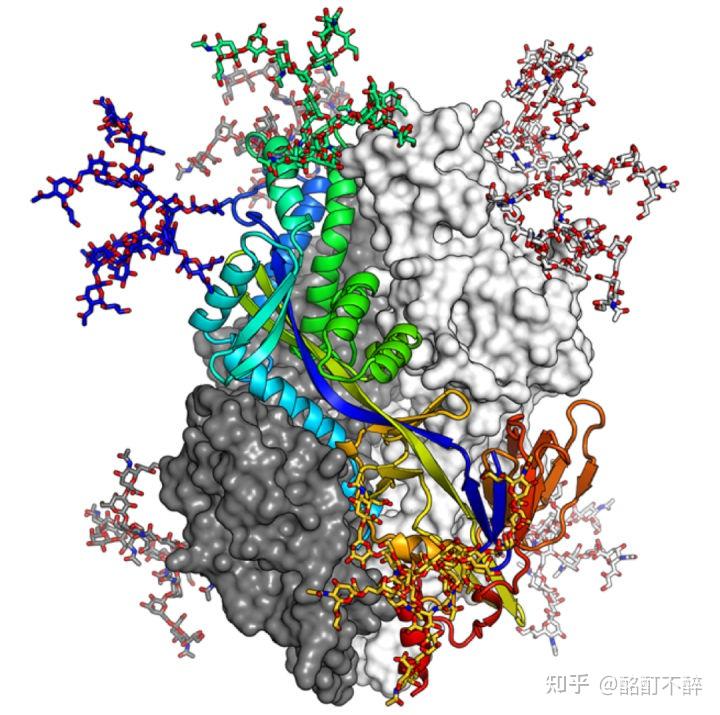
图 | 蛋白质 3D 结构(来源:Nat Commun)
因此,从 Christian B. Anfinsen Jr. 理论提出至今 50 多年的时间里,科学家始终无法解决蛋白质折叠的问题,对于蛋白质结构的了解依旧十分有限。
而近年来,随着冷冻电子显微镜技术的发展,可以在没有结晶样本的条件下观察蛋白质结构,使得蛋白质结构研究有所进展。不过,冷冻电镜是非常昂贵的设备,只有极少数的实验室才有条件配备,对于广大科研工作者非常不友好。因此,生命科学界亟需新的方法解决蛋白质折叠问题。
AI 助力解决蛋白质结构预测难题
随着计算机科学的发展,此前曾有学者提出利用计算机模型解决蛋白质折叠问题。虽然这一想法是可行的,但是在随后数十年的时间里,人们开发的各种计算机模型预测蛋白结构的准确性始终有限。
在过去 25 年中,国际蛋白质结构预测大赛(CASP)一直关注这个领域的进展,试图寻找能够完美解决蛋白质折叠问题的计算机模型。直到第 14 届大赛 CASP14 大赛成功举办,DeepMind 旗下的 AlphaFold 系统在蛋白质结构预测方面表现出了无与伦比的准确性。
该比赛的评价方式是将参赛者提供的解决方案与“黄金试验标准”进行对比,用 GDT 评分衡量准确性,范围为 0-100,GDT 分数在 90 分左右,即可视为对人类实验方法具备竞争力。而 DeepMind 旗下的 AlphaFold 系统总分竟然达到了 92.4,和实验的误差在 1.6,即使是在最难的没有同源模板的蛋白质上面,这个分数也达到了了恐怖的 87.0 。
同时,AlphaFold 的神经网络能在几分钟内预测出一个典型蛋白质的结构,还能预测较大蛋白质(比如一个含有 2180 个氨基酸、无同源结构的蛋白质)的结构。该模型能根据每个氨基酸对其预测可靠性进行精确预估,方便研究人员使用其预测结果。
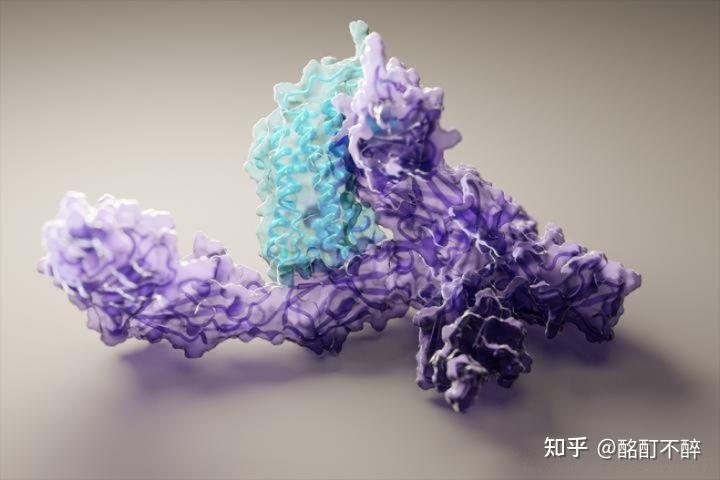
图 |研究人员使用 RoseTTAFold 预测的人类白细胞介素 12 与其受体结合的 3D 视图(来源:UW Medicine Institute for Protein Design)
随后,在今年 7 月份,华盛顿大学医学院生物化学系教授、蛋白质设计研究所所长 David Baker 领导一支计算生物学家团队,成功开发一款名为 RoseTTAFold 的工具,基于深度学习,能够根据有限的信息快速准确地预测出目标蛋白质的结构,达到与 AlphaFold2 不相上下的准确度。
不仅如此,RoseTTAFold 所需的计算耗能与计算时间均比 AlphaFold2 还要低:仅用一台游戏计算机,在短短十分钟内就可以可靠地计算出蛋白质结构。更值得注意的是,RoseTTAFold 的代码和服务器完全免费提供给科学界!
图 | David Baker(来源:华盛顿大学官网)
自 7 月以来,相关程序已被 140 多个独立科研团队从 GitHub 免费下载,来自世界各地的科学家现在正在使用 RoseTTAFold 来构建蛋白质模型,以加速相关领域的研究。
同样在今年 7 月份,DeepMind 创始人兼首席执行官 Demis Hassabis 也在 Nature 杂志上分享了AlphaFold的开源代码,并发表了系统的完整方法论,详尽细致说明 AlphaFold 是如何做到精确预测蛋白质3D结构的。也就是说,这款强大蛋白质结构预测模型已经是完全免费的。
至此,两种强大的基于人工智能的蛋白质结构预测模型全部免费开放,科研工作者可以随时利用这两款模型获取蛋白质的空间结构,而无需对蛋白质进行结晶或使用昂贵的冷冻电镜进行研究。
在同步配发的评论文章里,Science 杂志的主编 Holden Thorp 对此表示,“首先,它解决了困扰生命科学近 50 年的蛋白质折叠问题,好比物理学中的引力波,科学家们数十年如一日,坚持不懈最终才攻克这一难题;其次,这一技术改变了未来结构生物学的规则,就像冷冻电镜那样,加速生命科学的发展;此外,完全免费意味着它是真正适合所有人的蛋白质预测模型。”
参考资料:
https://www.eurekalert.org/news-releases/937705?
http://www.science.org/doi/10.1126/science.abn5795
来源:学术头条
阅读原文
回复
支持
反对
使用道具
举报
返回列表
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
医学关注
生物安全
标本处理
新品前瞻
液基细胞技术
FISH技术
关闭
官方推荐
/3
AI助手<小桔子>来了!
欢迎来交流,可以回答IVD行业各类问题!
查看 »
IVD业界薪资调查(月薪/税前)
长期活动,投票后可见结果!看看咱们这个行业个人的前景如何。请热爱行业的桔友们积极参与!
查看 »
小桔灯网视频号开通了!
扫描二维码,关注视频号!
查看 »
返回顶部
快速回复
返回列表
客服中心
搜索
洽谈合作
关注微信
微信扫一扫关注本站公众号
个人中心
个人中心
登录或注册
业务合作
-
投稿通道
-
友链申请
-
手机版
-
联系我们
-
免责声明
-
返回首页
Copyright © 2008-2024
小桔灯网
(https://www.iivd.net) 版权所有 All Rights Reserved.
免责声明: 本网不承担任何由内容提供商提供的信息所引起的争议和法律责任。
Powered by
Discuz!
X3.5 技术支持:
宇翼科技
浙ICP备18026348号-2
浙公网安备33010802005999号
快速回复
返回顶部
返回列表

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-11 14:24
发表于 2025-3-11 14:24


 提升卡
提升卡 发表于 2025-3-11 14:25
发表于 2025-3-11 14:25