金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
Part12023 年生物信息学十大进展
转载自:https://omicstutorials.com/top-10-advances-in-bioinformatics-in-2023/
在生物信息学的动态领域,2023年带来了一波变革性进步,有望彻底改变我们理解、分析和利用生物数据的方式。本文探讨了生物信息学的十大突破,这些突破正在重塑生命科学和医疗保健的格局。
1人工智能驱动的药物发现
人工智能(AI)和机器学习(ML)与生物信息学工具的整合加速了药物发现过程。AI算法可以分析大量数据集,预测分子相互作用,并以前所未有的速度和准确性识别潜在的候选药物。
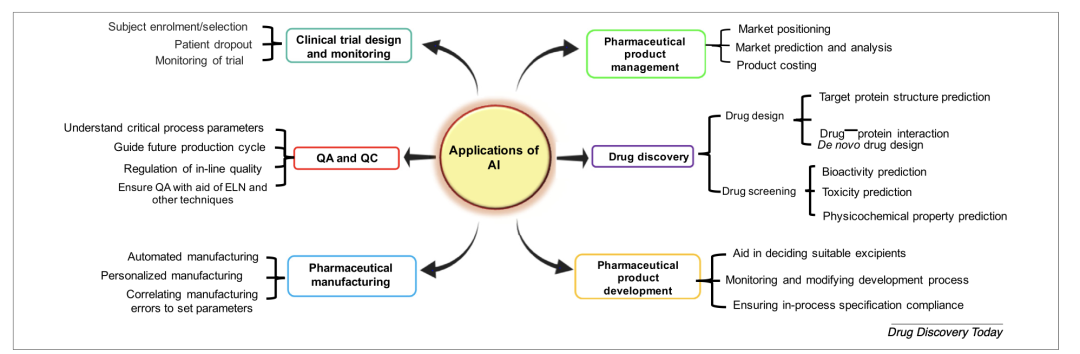
人工智能在药物发现和开发中的应用
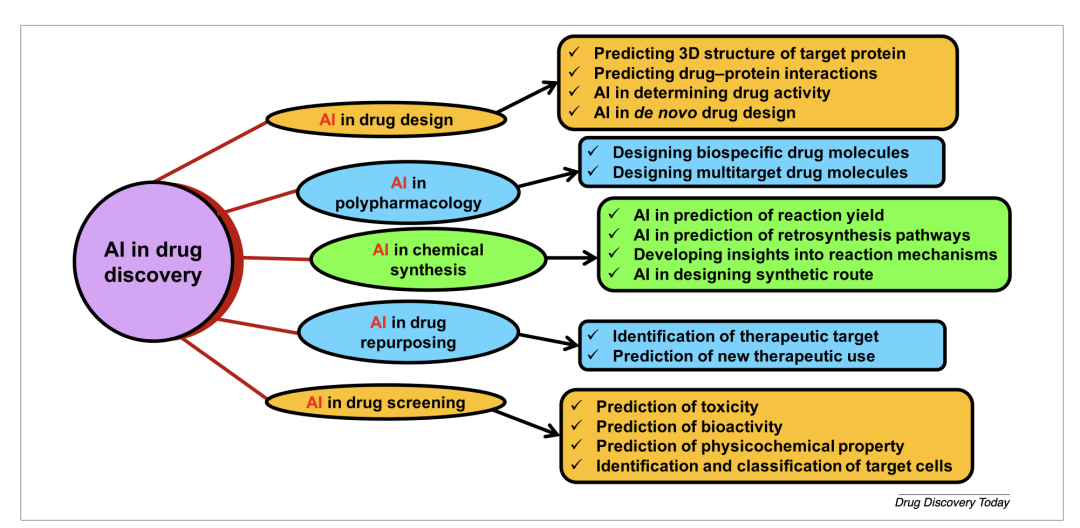
人工智能在药物发现中的作用
图片来源:Paul, D., Sanap, G., Shenoy, S., Kalyane, D., Kalia, K., & Tekade, R. K. (2021). Artificial intelligence in drug discovery and development. Drug discovery today, 26(1), 80–93. https://doi.org/10.1016/j.drudis.2020.10.010
2个性化医学和基因组学
由于遗传学和生物信息学的进步,个性化医学的时代正在蓬勃发展。尖端工具能够分析单个基因组,为基于一个人独特基因构成的定制治疗计划铺平了道路。

2023年4月13日,北京大学生物医学前沿创新中心(BIOPIC)张泽民教授受邀于Cell发表了题为Accelerating the understanding of cancer biology through the lens of genomics 的综述文章,全面总结了肿瘤基因组学的发展历程以及其对理解肿瘤驱动机制与异质性、促进个体化精准肿瘤治疗的重要贡献,并强调了目前肿瘤基因组学研究视野的转化,即从对癌细胞本身特性的关注提升到对整个肿瘤“生态系统”的研究,最后讨论了肿瘤基因组学未来在推动基础肿瘤生物学理解与临床转化应用方面潜在的发展方向。 3单细胞组学
单细胞组学技术已经达到了新的高度,使研究人员能够深入研究单个细胞的复杂性。这种粒度水平有助于更深入地了解细胞异质性,并促进癌症研究和发育生物学等领域更精确的分析。
北京大学生命科学学院、生物医学前沿创新中心(BIOPIC)汤富酬教授与文路副研究员受邀在Precision Clinical Medicine杂志上发表题了为“Recent advances in single-cell sequencing technologies”综述性文章。从单细胞表观基因组测序、单细胞基因组测序技术用于谱系追踪、单细胞空间转录组技术、基于第三代测序平台的单细胞基因组测序,四个方面系统总结了单细胞测序技术的最新进展,并探讨了单细胞测序技术的潜在应用和未来发展方向。
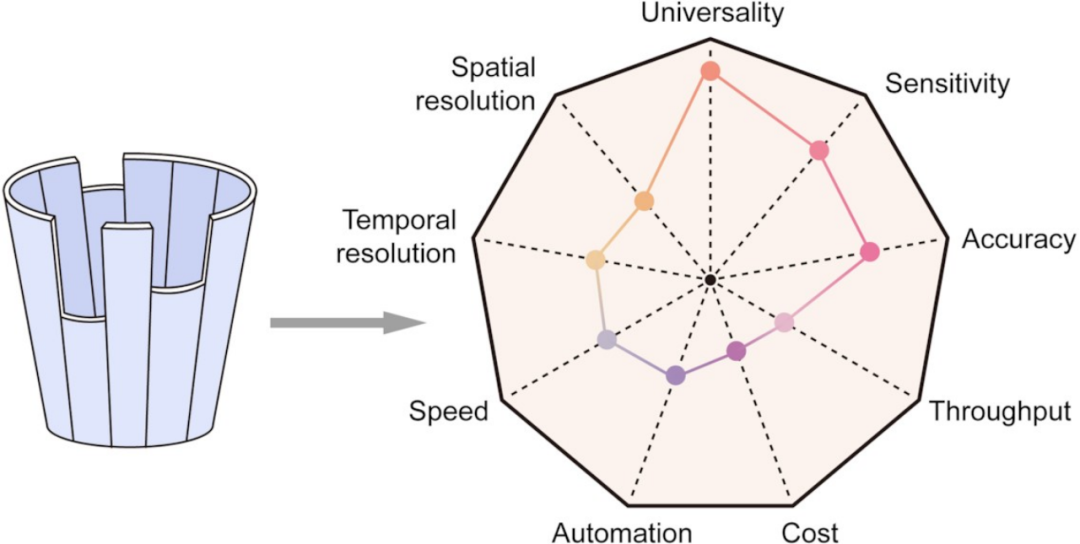
图片来源:Wen, L., & Tang, F. (2022). Recent advances in single-cell sequencing technologies. Precision clinical medicine, 5(1), pbac002. https://doi.org/10.1093/pcmedi/pbac002
单细胞多组学测序技术近年来进展迅速,但是仍然有诸多可改进之处。单细胞多组学测序技术有很强的普适性。它具备高灵敏度和高精确度但仍有待加强。它的通量、自动化和检测速度近年来迅速提高且成本不断下降,但是仍未达到临床检测等未来应用场景的要求。尤其对于人类在体干细胞研究,它的时空分辨率还有待大幅提高。

比利时鲁汶大学的研究团队在《Nature Reviews Genetics》发表题为“Methods and applications for single-cell and spatial multi-omics” 的综述,重点介绍了快速发展的单细胞和空间多组学技术(也称为多模态组学方法)领域的进展,以及跨分子层整合信息所需的计算策略。该文展示了单细胞和空间多组学对基础细胞生物学和转化研究的影响,讨论了当前的挑战,并对未来研究进行了展望。 4宏基因组学和微生物组研究
生物信息学在解开微生物组的奥秘方面发挥着关键作用。宏基因组方法正在揭示居住在人体内和人体上的复杂微生物群落,影响健康和疾病。
5结构生物信息学和冷冻电镜
结构生物信息学的进步,加上冷冻电子显微镜(cryo-EM),正在改变我们在原子水平上可视化生物分子结构的能力。这对药物设计、蛋白质工程和理解细胞过程有深远的影响。
6网络生物学
网络生物学的整体方法越来越突出,允许研究人员将生物系统分析为相互连接的网络。这种系统层面的视角增强了我们对细胞途径、疾病机制和遗传变异影响的理解。
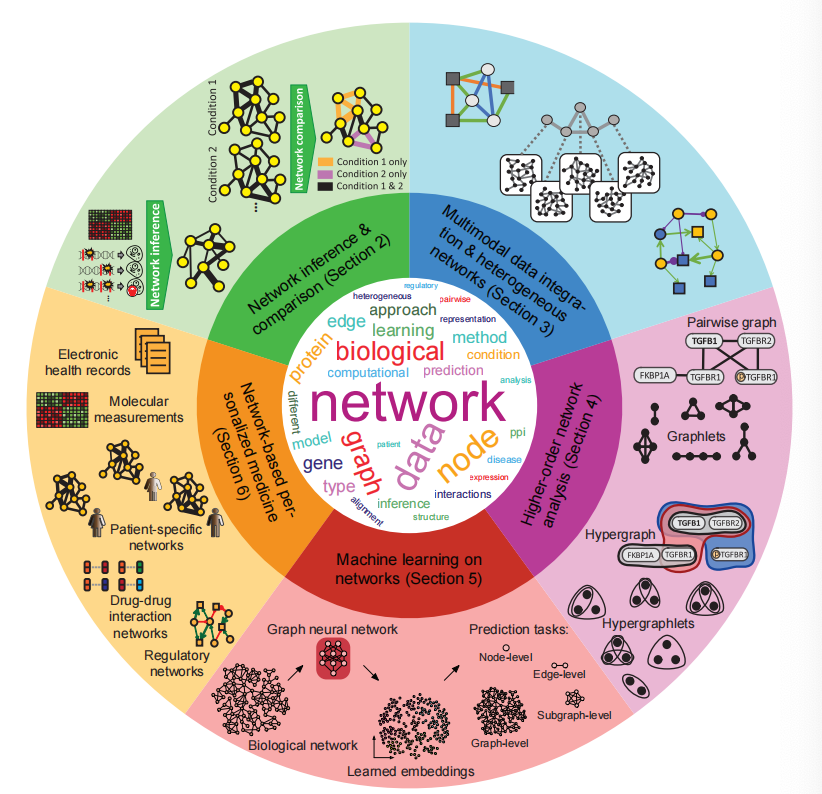
图片来源:Zitnik M, Li MM, Wells A, et al. Current and future directions in network biology. arXiv preprint arXiv:2309.08478, 2023.
网络生物学对于研究我们民族瑰宝中医药有重要作用,因为中医药有多靶点、多途径、多通路的特点,传统的生物学是不能将其特质全面阐述出来的!
7CRISPR生物信息学
基于CRISPR的技术已成为基因组编辑不可或缺的工具,生物信息学在设计和优化CRISPR实验方面发挥着至关重要的作用。计算工具有助于预测目标外效应,并完善基因编辑技术的精确度。
关于CRISPR的基础知识可看之前的推文
生信|基因组变异
8生物信息学中的区块链
区块链技术的集成解决了生物信息学中的数据安全、完整性和隐私问题。区块链确保基因组和临床数据的透明和安全共享,促进协作,同时保持机密性。
9生物信息学中的量子计算
量子计算正在成为生物信息学的游戏规则改变者,能够以前所未有的速度处理大量数据集和复杂算法。这对模拟生物过程、优化药物发现和解决复杂的计算问题有影响。

量子计算生物学的实际应用
10道德考虑和负责任的人工智能
随着生物信息学的不断发展,围绕数据隐私、同意和负责任的人工智能实施的道德考虑越来越突出。该领域正在积极解决这些问题,以确保在道德上取得进展,并重点关注社会福祉。
总之,2023年见证了一系列非凡的生物信息学突破,这些突破正在重塑生命科学的格局。从人工智能驱动的药物发现到围绕这些进步的道德考虑,生物信息学处于解开生命奥秘的最前沿,突破了理解和利用生物信息的界限。随着这些技术继续成熟,并在研究、医学等领域找到新的应用,未来有望实现更令人兴奋的发展。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-1 16:38
发表于 2025-3-1 16:38


 提升卡
提升卡 发表于 2025-3-1 16:39
发表于 2025-3-1 16:39