金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
数据集
主要数据集基本信息如下:
(23条消息) 文字识别/文本检测数据集_Sesen的木屋-CSDN博客_文字识别数据集
算法
- CRAFT 本论文为2019年韩国学者提出的一种字符级的文本检测算法
主要思想:
1、 图像分割的思想, 采用u-net结构, 先下采样再上采样;
2、 非像素级分割, 而是将一个character视为一个检测目标对象;
3、 本文提出了一种弱监督学习思路, 先利用合成样本进行预训练, 再将预训练模型对真实数据集进行检测, 得到预测结果, 经过处理后得到高斯热度图作为真实数据集的字符级标签。
模型结构:
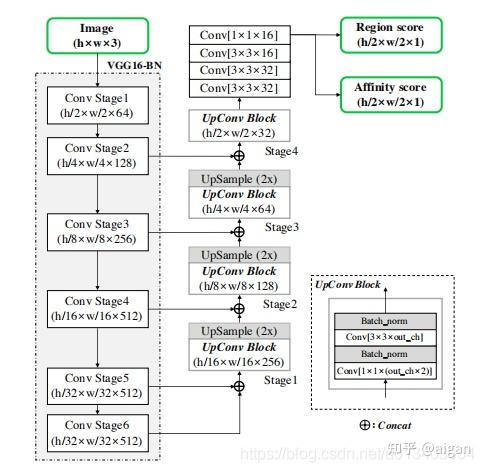
最终输出两个通道的结果,尺寸为原图1/2,本文件建议使用32的整数倍作为输入尺寸,防止出现像素漂移。两个通道可以认为是region score map和affinity score map,两个图类似于高斯热点图。示意如下:
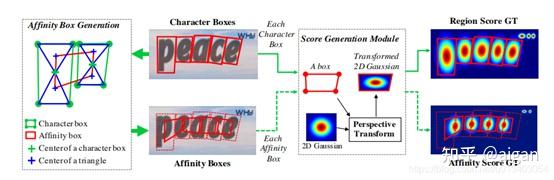
Region代表的是每个字符的中心,affinity代表的是字符连接中心,两个联合起来就能代表哪些是字符和哪些字符是属于同一个词。
训练过程比较复杂,如下图所示:
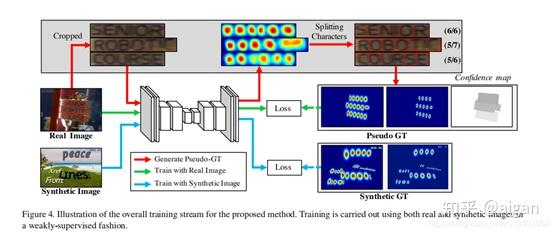
对真实数据会进行处理,将bbox内字符拉伸为较正的文本框,然后利用分水岭的方式获得分割字符,然后用特殊评分方式判断分割效果。

真实数据集基本都标注了其文本框对应的识别结果.所以其文本框对应的字符长度信息是知道的. 比如对于文本框w, 假如其识别标签为"label", 那么l(w)=5.而分水岭算法分割出字符后也可以知道其字符长度信息lc(w), 可以计算得到其标签评分s, 假如分水岭算法分割得到的字符长度和真实字符长度一致, 那么s=1, 长度相差越大, 评分越低, 说明分水岭分割出来的结果越不可信。
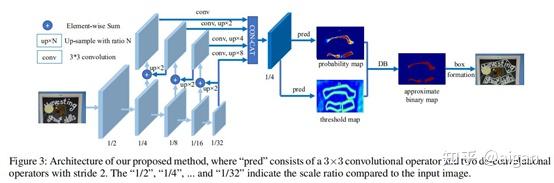
如图所示,网络利用不同stage进行特征融合,然后再转换到统一尺寸,然后输出文本概率图P和阈值图T,利用这两个图得到最终的二值图B。
训练时二值图无法微分,因此利用近似二值图替换二值图,从梯度传播上也可以解释为何二值交叉熵效果更差。
训练中对数据的处理如下:
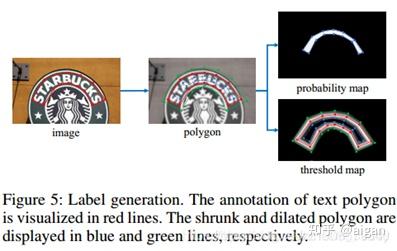
P与B的label一致,都是由Gt缩小一定偏移生成;T的label相对复杂一点,最终效果是Gt附近一定距离内的空间,类似下图,

亮线为Gt。
推理时,利用P或B(B更准确)获得二值图,然后用二值图获得文本连通域,最后将连通域做一定放大即是文本框。
- PANNet 2019年8月旷视在ICCV上的一篇论文
该网络主要包括低成本的分割模块与可学习的后处理方法。
低成本的分割模块由特征金字塔增强模块(Feature Pyramid Enhance Module,FPEM)和特征融合模块(Feature Fusion Module,FFM)组成。
FPEM是可级联的U形模块,可引入多级信息以及指导更好的分割。FFM可将不同深度的FPEM给出的特征汇合到最终的分割特征中。
可学习的后处理由像素聚合(Pixel Aggregation,PA)部分实现。通过预测的相似性向量(similar vector)聚合文本像素。
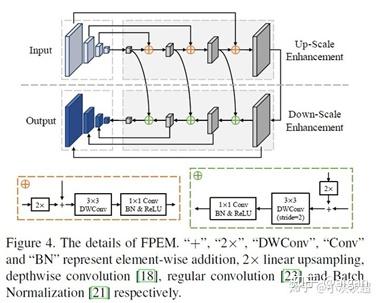
文章中采用resnet18作为主干网络,该轻量级的主干网络感受野较小,表达能力也不足,因此提出了FPEM和FFM。FPEM的模块结构如下:
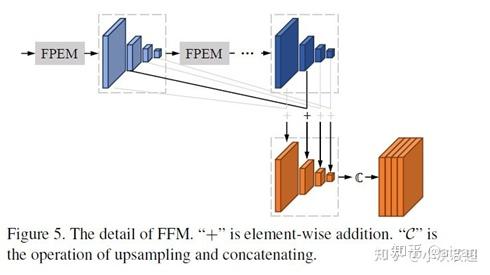
FFM结构如下:
最后,使用1x1 conv得到6通道的输出。网络的输出包括:
text region, 1个通道
kernel, 1个通道
similar vector, 4个通道
关于后处理:
原理就是利用学习到的similar vector 1. 通过连通阈获得初始的kernel(即文本实例的骨架)及其实例可能的像素 2. 对于Ki,按四个方向融合像素,判断依据为该像素p与Ki的similar vector之间的距离d = 3, 则认为该像素属于该类。 3. 重复2操作,直至Ki都融合到自己的像素。((23条消息) pannet文本检测网络模型和后处理详解_ethonyLight的博客-CSDN博客对本部分有详细解释)
其中有个先到先得的原则。
该算法在ICDAR2013上取得F1分数94.3%,在ICDAR2015上F1分数92.1%,在Total-Text上87.1%,在CTW-1500上86.6%。
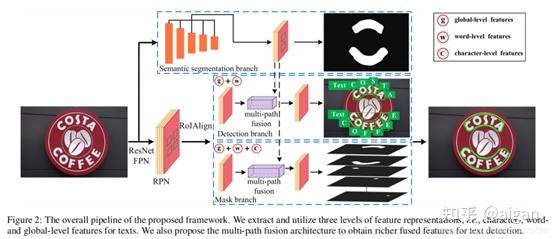
TextFuseNet网络结构主要分为三个分支:
第一个是语义分割分支( semantic segmentation branch),该分支用来提取液全局级别的特征;
另外二个是检测分支和mask分支(detection and mask branches),用来提取字符级别和单词级别的特征;
在得到三种层次的特征后,使用多路径特征融合体系结构(Multi-path Fusion Architecture),融合三者特征,生成更具代表性的特征表示,从而产生更准确的文本检测结果。
根据以上原理,不太适合用于中文文本检测,因此暂时不详细介绍。
原文地址:https://zhuanlan.zhihu.com/p/363561976 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-2-27 11:23
发表于 2025-2-27 11:23
 提升卡
提升卡


