金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
一、参数和非参数检验
1、参数检验
参数检验,是在总体分布已知的情况下,对总体分布的参数如均值、方差等进行推断的方法。
参数检验的方法有,T检验、Z检验、F检验、二项分布总体的假设检验等,这些检验都是假设样本来自于正态分布的总体,将总体的数字特征看做未知的参数,通过样本的数据特征对其总体进行统计推断。
2、非参数检验
由于种种原因,人们往往无法对总体分布形态做简单假定,此时参数检验方法就不适用了。
非参数检验,是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。非参数检验推断过程中不涉及有关总体分布的参数。
常用的非参数检验的方法有,两个独立样本的K-S检验、W-W检验、U检验等,多个独立样本的H检验、中位数检验等,卡方检验,二项分布检验、拟合优度检验等。
二、T检验
1、t分布
t分布用于根据小样本来估计呈正态分布且方差未知的总体的均值。
t分布曲线形态与n(自由度df)有关,与标准正态分布曲线相比,自由度df越小,t分布曲线越平坦;自由度df越大,t分布曲线越接近正态分布曲线。
t分布是不同自由度下关于统计量t的概率密度函数f(t),实际上,在进行t检验时根据自由度和显著性水平得到的就是标准t分布下的t值,进而与实际的检验统计量t比较,来得出结论。

t检验是一种手法,用于判断两组间平均差是否有统计学意义,而在判断统计学意义的时候就需要用到t分布;即t分布是用来t检验的。
2、什么是T检验?
T检验,又称t test,用于样本量较小(n<30)且总体标准差σ未知的正态分布。它是使用t分布理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。
为什么小样本用t检验?
从抽样研究所得的样本均数特点来看,只要样本量>30,(无论总体是否服从正态分布)抽样研究的样本均数服从或者近似服从正态分布;而如果样本量较小(参考样本量<30),抽样分布随着样本量的减小,与正态分布的差别越来越大。此时需要用小样本理论来解释样本均数的分布,而t分布就是小样本理论的代表。因此,小样本的检验需要用到t检验。
3、T检验的前提条件?
①只有1个或2个样本,没有多个样本。
②样本服从正态分布或近似正态分布。若不满足则可以利用一些变换(对数、开根号、倒数等)将其转换为服从正态分布的数据;若还是不满足,只能利用非参数检验方法。
③随机样本。
④判断方差同质性检验。即两个均值比较时,要两个样本总体方差相等。
4、T检验的类型
t检验可分为单样本t检验、双独立样本t检验、配对样本t检验。
(1)单样本t检验
(i)定义
单样本t检验是检验一个样本平均数与一个已知的总体平均数的差异是否显著。
当总体分布是正态分布、总体标准差未知且样本量小于30时,样本平均数与总体平均数的离差(即差量)统计量呈t分布。
根据t分布的抽样分布定理:设 X_{1},X_{2},……,X_{n} 是来自正态分布N(μ,σ^2)的一个样本,样本平均数 \bar{x}=\frac{\sum_{1}^{n}{x_{i}}}{n} ,样本方差 S^2=\frac{\sum_{1}^{n}{(x_{i}-\bar{x})^{2}}}{n-1} ,则有\frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}\sim~t(n-1)服从于自由度为n-1的t分布。可知单总体t检验统计量t=\frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}。
如果是大样本则 t=\frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}} ,如果是小样本则t=\frac{\bar{X}-\mu}{\frac{S}{\sqrt{n-1}}}。
(ii)检验原理
根据样本数据计算t检验统计量 \frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}} 的绝对值;在通过自由度n-1和显著性水平α/2查找t分布表得到标准t值:
①对于双侧检验,若\left| \frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}\right|>t_{(α/2,n-1)} ,则拒绝原假设,认为样本均值与总体均值不等;否则不拒绝原假设。
②对于左尾检验,若\left| \frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}\right|<t_{(α/2,n-1)} ,则拒绝原假设,认为样本均值与总体均值不等;否则不拒绝原假设。
③对于右尾检验,若若\left| \frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}}\right|>t_{(α/2,n-1)} ,则拒绝原假设,认为样本均值与总体均值不等;否则不拒绝原假设。
(iii)python调用实现单样本t检验
一是使用statsmodels.stats.weightstats模块下的DescrStatsW.ttest_mean()进行单样本t检验。
statsmodels.stats.weightstats.DescrStatsW.ttest_mean(value=0,alternaitve="two_sided")
value是假设的均值,alternative是备择假设的形式,可选‘two-sided’双边检验, ‘larger’右尾检验, ‘smaller’左尾检验。
from statsmodels.stats import weightstats as sw
pop_mean=82
data=[76,65,67,54,87,85,86,94,67,73,71,72,83,87,67,87,78,79,76,98,76,84,85,93,72]
t,p,df=sw.DescrStatsW(data).ttest_mean(value=pop_mean,alternative="smaller")
a,b=sw.DescrStatsW(data).tconfint_mean()
print("t统计量值={},p值={},自由度={}".format(t,p,df))
print("差值95%置信区间下限={},上限={}".format(a,b))

#可通过scipy.stats模块的t模块使用t分布,计算出标准的t值,用于和检验统计量t值比较
#t.ppf(1-显著性水平α,自由度)
#pdf为概率密度函数,刻画的是随机变量落在区间的概率;
#而这里是要计算临界值,即t值,使用概率密度函数的逆函数ppf,可得到临界值,即t分布表对应的t值
from scipy.stats import t
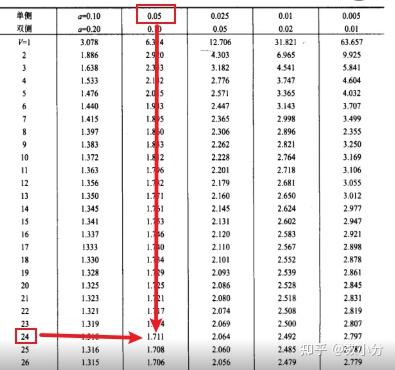
t0=t.ppf(0.95,24)
print("显著性水平为0.05,自由度为24,对应的标准临界值c={}".format(t0))
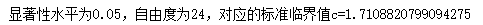
二是使用过scipy.stats模块下的ttest_1samp()进行单样本t检验。
scipy.stats.ttest_1samp(a,popmean,axis=None,nan_policy="propagate",alternative="two_sided")
a表示样本数据;popmean表示零假设期望值,即总体均值;axis计算的轴,如果没有则计算整个数组;nan_policy定义输入包含nan值时如何处理,默认propagate返回nan值、raise显示错误、omit忽略nan值执行计算。
注意,该函数没有alternative。实际其计算的是双边检验,如果备择假设<符号,当t>=0时,进行判定单侧p值=1-p值/2,t<0时进行判定p值=p/2;去>符号时,t>=0时则判定P值=p值/2;t<0时判定p值=1-p值/2。
from scipy import stats
pop_mean=82
data=[76,65,67,54,87,85,86,94,67,73,71,72,83,87,67,87,78,79,76,98,76,84,85,93,72]
t,p=stats.ttest_1samp(data,pop_mean)
print("t统计量值={},p值={}".format(t,p))(2)双独立样本t检验
(i)定义
双独立样本t检验,检验两个独立样本的平均数与其各自所代表的总体的差异是否显著。
已知两总体为X1~N(μ1,σ1^2),X2~N(μ2,σ2^2),则样本均值为 \bar{x}_{1}=\frac{\sum_{1}^{n}{x_{1i}}}{n_{1}} ,\bar{x}_{2}=\frac{\sum_{1}^{n}{x_{2i}}}{n_{2}};样本方差为 S_{1}^{2}=\frac{\sum_{1}^{n_{1}}{(x_{1i}-\bar{x}_{1})^{2}}}{n_{1}-1} , S_{2}^{2}=\frac{\sum_{1}^{n_{2}}{(x_{2i}-\bar{x}_{2})^{2}}}{n_{2}-1}。
根据方差是否相等可分2种:
①总体方差相等且未知,样本方差满足0.3<S1^2/S2^2<2;则有t=\frac{(\bar{X}_{1}-\bar{X}_{2})-(\mu_{1}-\mu_{2})}{\sqrt{(\frac{(n_{1}-1)S_{1}^{2}+n_{2}-1)S_{2}^{2}}{n_{1}+n_{2}-2})*(\frac{1}{n_{1}}+\frac{1}{n_{2}})}},同时H0成立时有μ1=μ2即μ1-μ2=0,则有:t=\frac{\bar{X}_{1}-\bar{X}_{2}}{\sqrt{(\frac{(n_{1}-1)S_{1}^{2}+n_{2}-1)S_{2}^{2}}{n_{1}+n_{2}-2})*(\frac{1}{n_{1}}+\frac{1}{n_{2}})}}
②总体方差不相等且未知;则有 t=\frac{\bar{X}_{1}-\bar{X}_{2}}{\frac{S_{1}^{2}}{n_{1}} +\frac{S_{2}^{2}}{n_{2}}} ,同时自由度v≈\frac{(\frac{S_{1}^{2}}{n_{1}}+\frac{S_{2}^{2}}{n_{2}})^{2}}{\frac{S_{1}^{4}}{(n_{1}-1)n_{2}^{2}}+\frac{S_{2}^{4}}{(n_{2}-1)n_{2}^{2}}}
③如果总体方差已知,则双独立样本的检验可用z检验; z=\frac{(\bar{x}_{1}-\bar{x}_{2})-(μ_{1}-μ_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}
(ii)检验原理类似,不再赘述。
(iii)python调用实现双独立样本t检验
①两个独立样本均值之差的t检验
一是使用scipy.stats模块的ttest_ind()进行独立样本t检验。
scipy.stats.ttest_ind(a,b,axis=none,equal_var=True,alternative=""two-sided)
a/b为两组样本数据,具有相同的shape(行列数);axis数组的读取方向,如果没有则计算整个数组a、b;equal_var默认true,执行假设总体方差相等的标准独立双样本检验,为false则执行welchde t-test,不假设方差相等;alterative定义备择假设,two-sided为双边检验,less为左尾检验,greater为右尾检验。
返回的是t检验统计量值和p值。
from scipy.stats import ttest_ind,levene
x = [20.5, 19.8, 19.7, 20.4, 20.1, 20.0, 19.0]
y = [20.7, 19.8, 19.5, 20.8, 20.4, 19.6, 20.2]
t0,p0=levene(x,y) #检验p值大于0.05认为是满足方差齐性,若不满足则加一个参数equal_var=False
t,p=ttest_ind(x,y,alternative="two-sided",equal_var=False)
print("t值={},p值={}".format(t,p))二是使用statsmodels.stats.weightstats库的ttest_ind()进行独立样本t检验。
#statsmodels.stats.weightstats.ttest_ind(x1, x2, alternative='two-sided', usevar='pooled', value=0)
#x1x2为两组样本数据,有相同的行列数shape;alternative为备择假设的形式,可选‘two-sided’双边检验, ‘larger’右尾检验, ‘smaller’左尾检验;usevar是否要求方差齐性,pooled要求,unequal不要求;value指定原假设取等号时的检验值。
import statsmodels.stats.weightstats as st
arr1=[7,6,5,4,2,6]
arr2=[6,7,7,4,5,9]
t,p,df=st.ttest_ind(arr1,arr2,alternative="two-sided",usevar="unequal")
print("t值={},p值={},自由度={}".format(t,p,df))(3)配对样本t检验
(1)定义
配对样本t检验,用于检验匹配而成的两组被试获得的数据,或同组被试在不同条件下所获得的数据的差异性。这里的两组样本数据是匹配的,存在关联的。如比较两种测量方法的差异,每对数据是针对同一个对象的测量。
配对样本可视为单样本t检验的扩展。
配对样本有X,Y,总体平均数为μ0,配对样本之差di=xi-yi,i=1~n,配对样本之差的平均值 \bar{d}=\frac{\sum_{1}^{n}{d_{i}}}{n} ,配对样本之差标准差 S_{d}=\sqrt{\frac{\sum_{1}^{n}{(d_{i}-\bar{d})^{2}}}{n-1}} ;而检验统计量 t=\frac{\bar{d}-\mu_{0}}{\frac{S_{d}}{\sqrt{n}}} 。该统计量t在零假设μ=μ0为真的条件下服从自由度为n-1的t分布。
(ii)检验原理类似,不再赘述。
(iii)python调用实现配对样本t检验
使用scipy.stats模块的ttest_rel()进行配对样本t检验。
scipy.stats.ttest_rel(a,b,axis=0,nan_policy="propagate",alternative="two-sided")
a,b表示两组相关样本数据,具有相同的shape;axis如果没有则计算整个数组a、b;nan_policy定义输入包含nan值时如何处理,默认propagate返回nan值、raise显示错误、omit忽略nan值执行计算;alterative定义备择假设,two-sided为双边检验,less为左尾检验,greater为右尾检验。
from scipy.stats import ttest_rel
data1=[]
data2=[]
t,p=ttest_rel(data1,data2,alternative="less")
print("t值={},p值={}".format(t,p))三、Z检验
1、Z分布(标准正态分布)
正态分布是有均值μ和标准差σ定义的一种概率分布;若一个连续随机变量X符合均值μ和标准差σ的正态分布,则写为X~N(μ,σ^2)。
如果均值μ=0,标准差σ=1,则X~N(0,1)符合标准正态分布。
实际上,对于一个正态分布,可以通过标准化转化为标准正态分布,转化方法是z=(x-μ)/σ,可通过概率分布函数证明。因此标准正态分布又称为z分布,是正态分布的一种。
2、什么是Z检验
Z检验用来判断样本均值是否与总体均值具有显著性差异的方法。通过正态分布理论来推断差异发生的概率,从而比较两个均值的差异是否显著。
3、Z检验的前提条件
(1)服从正态分布
(2)总体标准差已知或样本量足够大(n>30)
4、Z检验的类型
(1)单样本均值z检验
(i)定义
检验一个样本平均数与一个已知的总体平 均数的差异是否显著。
Z检验统计量 z=\frac{\bar{X}-μ}{\frac{σ}{\sqrt{n}}} ,在总体标准差未知时,可用样本标准差代替,即z=\frac{\bar{X}-μ}{\frac{S}{\sqrt{n}}}。¯X为样本均值;μ为总体均值;σ为总体标准差;n为样本容量。
(ii)python实现单样本均值z检验
①statsmodels.stats.weightstats.ztest(x1,x2,value=0,alternative="two-sided")可用于单样本和双样本均值的z检验,设置参数x2=none则为单样本的检验。
②statsmodel.stats.weightstats.DescrStatsW.ztest_mean(value=0,alternative="two-sieded")
value是假设的均值,alternative是备择假设的形式,可选‘two-sided’双边检验, ‘larger’右尾检验, ‘smaller’左尾检验。
from statsmodels.stats import weightstats as sw
pop_mean=82
data=[76,65,67,54,87,85,86,94,67,73,71,72,83,87,67,87,78,79,76,98,76,84,85,93,72]
z,p,df=sw.DescrStatsW(data).ztest_mean(value=pop_mean,alternative="smaller")
a,b=sw.DescrStatsW(data).tconfint_mean()
print("z统计量值={},p值={},自由度={}".format(z,p,df))
print("差值95%置信区间下限={},上限={}".format(a,b))补充:可通过scipy.stats的norm模块调用ppd函数,依据显著性水平找到对应的z临界值。
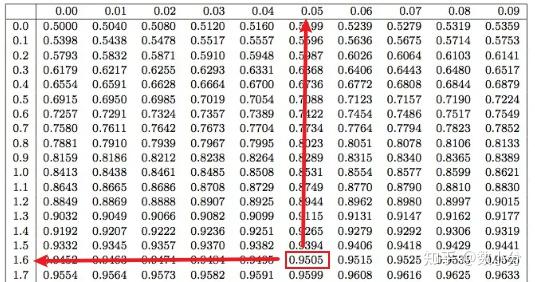
scipy.stats.norm.ppd(1-显著性水平α)
from scipy.stats import norm
a=norm.ppf(0.95)
print("显著性水平为0.05对应的z统计量临界值={}".format(a))
(2)双独立样本均值z检验
检验来自两个的两组样本平均数的差异性,从而判断它们各自代表的总体差异是否显著。
则检验统计量 z=\frac{\bar{X}_{1}-\bar{X}_{2}}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}} 。如果两个样本的总体标准差σ1、σ2未知,则可用样本标准差s1,s2代替。
¯X1、¯X2为两个样本数据的平均值;σ1、σ2为总体标准差;s1、s2为样本标准差;n1、n2为样本量。
(ii)python实现双样本均值z检验
①statsmodels.stats.weightstats.ztest(x1,x2,value=0,alternative="two-sided")
x1x2为独立样本数据,其中一个为none时,进行单总体检验;value为假设值,单样本情况下值是零假设x1的平均值,双样本情况下值是在零假设下x1x2的平均值间的差值;alternative为备择假设形式,可选‘two-sided’双边检验, ‘larger’右尾检验, ‘smaller’左尾检验;
import statsmodels.stats.weightstats as sw #单样本和双样本的z检验都是用该函数
arr1 = [23,36,42,34,39,34,35,42,53,28,49,39,46,45,39,38,45,27,43,54,36,34,48,36,47,44,48,45,44,33,24,40,50,32,39,31]
arr2 =[41,34,36,32,32,35,33,31,35,34,37,34,31,36,37,34,33,37,33,38,37,34,36,36,31,33,36,37,35,33,34,33,35,34,34,34]
t,p=sw.ztest(arr1,arr2,value=0,alternative="two-sided")
print("z值={},p值={}".format(t,p))②补充:两个独立样本比例之差的z检验(比例差异时通常用z检验)
statsmodels.stats.proportion.proportions_ztest([count1,count2],[nobs1,nobs2],value=0,alternative='two-sided', prop_var=False)
[count1,count2]参数表示两个概率的分子(即成功次数);[nobs1,nobs2]表示两个概率的分母(即观测次数);value为假设值,单样本情况下值是零假设x1的平均值,双样本情况下值是在零假设下x1x2的平均值间的差值(一般为0);alternative为备择假设形式,可选‘two-sided’双边检验, ‘larger’右尾检验, ‘smaller’左尾检验;prop_var为false时则根据样本比例计算比例估计的方差,常见的是零假设下使用比例来指定比例估计的方差;
from statsmodels.stats.proportion import proportions_ztest
z,p=proportions_ztest([81,48],[180,150],alternative="two-sided") #即概率是81/180,48/150
print("z值={},p值={}".format(z,p))四、卡方检验
1、卡方分布
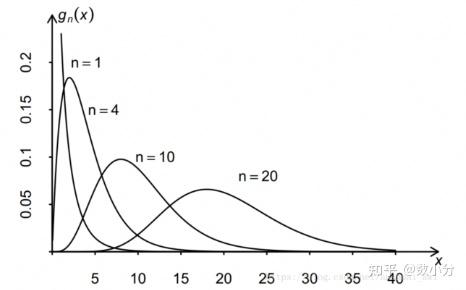
若N个相互独立的随机变量X1、X2、X3……Xn均服从标准正态分布(即独立同分布于标准正态分布),即Xi~N(0,1),则这n个服从标准正太分布的随机变量的平方和 X=\sum_{1}^{n}{X_{i}^{2}} 构成新的随机变量,成X是自由度n的卡方变量,其分布称为自由度n的卡方分布,记X~ χ_{n}^2 。
2、什么是卡方检验
卡方检验就是统计样本的实际观测值和理论推断值之间的偏离程度,偏离程度决定卡方值的大小,卡方值越大,二者偏离程度越大;如果两个值完全相同则卡方值为0。卡方检验是非参数检验,适用于布尔型数据和二项分布数据。
卡方统计量 χ^2=Σ\frac{(fa-fe)^{2}}{fe} ,其中fa表示观察值频数,fe表示期望值频数。
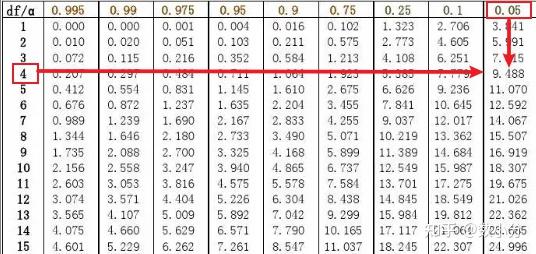
卡方统计量的分布与自由度有关;自由度v=(行数C-1)*(列数R-1)。
卡方检验针对分类变量。可用于推断两个或两个以上总体率或构成比是否有差别等,多用于拟合优度检验和独立性检验。
3、卡方检验的前提条件
(1)随机样本数据
(2)最好是大样本数据,针对表格的理论频数不能太小。
①若样本量n>=40,且任意一个格子的理论频数Tij>=5,可直接使用卡方检验公式,即χ^2=Σ((fa-fe)^2/fe);
②若样本量n>=40,但出现一个格子的理论频数1<=Tij<5,可需进行连续性校正,即χ^2=Σ((|fa-fe|-0.5)^2/fe);
③若样本量n<40,或任意一个格子的理论频数Tij<1,则不适用卡方检验,则用Fisher's检验。
4、卡方检验的类型
进行卡方检验时,如果只是由于抽样误差造成的实际频数和理论频数的差异,那卡方检验值应该很小,因为我们相信抽样是较合理的,误差不会特别大;如果卡方检验值太大,就不太能够用误差来解释,只能说明原假设不成立,即各种之间的数据本来就有差异。即根据检验统计量值和标准卡方值来比较,决定是否拒绝原假设。
(1)拟合优度检验
拟合优度检验,是依据总体分布状况,计算出分类变量中各类别的期望频数,与分布的观察频数进行对比,判断期望频数与观察频数是否有显著差异,从而达到对分类变量进行分析目的。
(i)案例:
泰坦尼克号沉没,船上共2208人,男性1738人,女性470人;海难后,幸存者718人,男性374人,女性344人。以α=0.1的显著性水平检验存活状况与性别是否有关。
H0:观察频数与期望频数一致;H1:观察频数与期望频数不一致。
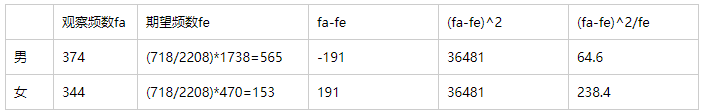
统计量 χ^2=Σ\frac{(fa-fe)^{2}}{fe} =64.6+238.4=303,自由度v=R-1,R为分类变量的个数(男、女);
通过查表得到自由度为1、显著性水平为0.1的 χ^2(0.1,1) 临界值为2.705; χ^2(0.1,1) < χ^2 (类似P值的比较),即拒绝原假设,认为存活状况与性别有关。
(ii)python实现拟合优度检验
可用scipy.stats.chisquare实现拟合优度的卡方检验。
scipy.stats.chisquare(f_obs,f_exp=None,ddof=0,axis=0)
f_obs表示在每个类别中观察的频数;f_exp表示每个类别中的预期频数;ddof表示调整自由度(频数-1-自由度ddof),默认为0;axis表示广播轴,默认0;
返回卡方统计量值chisq,p值。
from scipy.stats import chisquare
import numpy as np
data1=np.array([374,344])
data2=np.array([565,153])
k,p=chisquare(data1,data2)
print("统计量值=%.4f,p值=%.4f" %(k,p))
(2)独立性检验
拟合优度检验是对一个分类变量的检验;独立性检验,是对两个分类变量的分析,通过列联表的方式呈现,看看两个分类变量是否存在联系。
(i)案例:
一种原料来自三个不同地区,原料质量分为三个不同等级;从一批原料中随机抽取500件进行检验,结果如图;检验各个地区和原料质量之间是否存在依赖关系(α=0.05)?
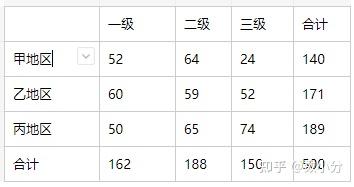
H0:地区和原料等级之间是独立的(不存在依赖关系),H1:地区和原料等级之间不独立(存在依赖关系)
甲地区合计140,可用140/500作为甲地区原料比例的估计值;一级原料合计162,可用162/500作为一级原料比例的估计值。
如果地区和原料等级之间是独立的,可计算出甲地区一级原料的期望比例,即第一单元:A=样本单位来自甲地区的事件,B=样本单位属于一级原料事件;P(第一单元)=P(AB)=P(A)P(B)=(162/500)*(140*500)=0.09072;
相应的频数期望值为0.09072*500=45.36;
计算一个单元中频数的期望值 f_{e}=\frac{RT}{n}*\frac{CT}{n}*n=\frac{RT*CT}{n} ;其中fe表示给定单元中的频数期望值;RT、CT为给定单元中所在行、所在列的合计;n为观察值的总个数,即样本量。
据此可计算出所有单元的期望值和卡方结果:
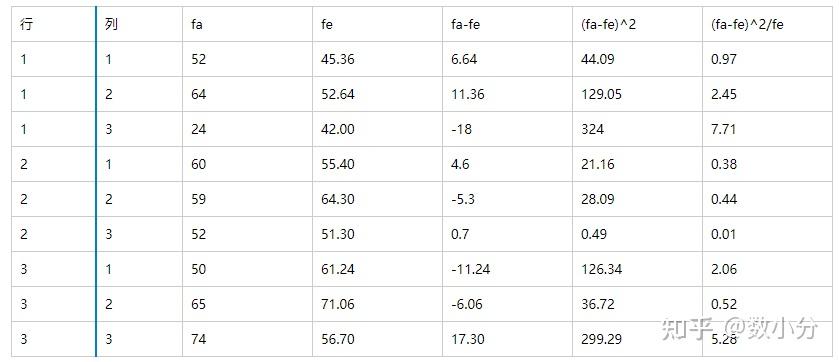
统计量χ^2=Σ((fa-fe)^2/fe)=0.97+2.45+7.71+0.38+0.44+0.01+2.06+0.52+5.28=19.82,自由度v=(3-1)*(3-1)=4
通过查表得到自由度为4、显著性水平为0.05的 χ^2(0.05,4) 临界值为9.488; χ^2(0.05,4) < χ^2 ,即拒绝原假设,即地区和原料等级之间存在依赖关系,原料质量受地区影响。
(ii)python实现卡方检验
可通过scipy.stats的chi2_contingency函数实现卡方检验;
scipy.stats.chi2_contingency(observed,correction,lambda)
observed表示列联表,包含每个类别观察到的频数;correction为true时且自由度为1表示应用yates的连续性校正,将每个观察值向相应的预期值调整0.5;lambda默认计算统计量是pearson的卡方统计量;
返回chi2检验统计量,p值,自由度df,expected预期频率。
from scipy.stats import chi2_contingency
import numpy as np
import pandas as pd
data=[[52,64,24],[60,59,52],[50,65,74]]
df=pd.DataFrame(data,index=["甲地区","乙地区","丙地区"],columns=["一级","二级","三级"])
k,p,df,e=chi2_1contingency(df)
print("统计量卡方值=%.3f,p值=%.4f,自由度=%i,expected_frep=%s" %(k,p,df,e))
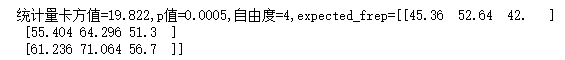
补充:可通过scipy.stats的chi2模块调用卡方分布,调用ppf()函数计算出对应自由度和显著性水平下的卡方临界值。
scipy.stats.chi2.ppf(1-显著性水平,自由度)
from scipy.stats import chi2
a=chi2.ppf(0.95,4)
print("显著性水平为0.95、自由度为4对应的卡方检验临界值={}".format(a))
五、F检验
1、F分布
若总体X~N(0,1),而(X1,X2,……,Xn)和(Y1,Y2,……,Yn)为来自X的两个独立样本,设统计量 F=\frac{\frac{\sum_{1}^{n_{1}}{X_{i}^{2}}}{n_{1}}}{\frac{\sum_{1}^{n_{2}}{X_{i}^{2}}}{n_{2}}} ,称统计量F服从自由度n1和n2的F分布,即为F~F(n1,n2)。
若总体X~N(0,1)与Y~N(0,1),而(X1,X2,……,Xn)来自X的一个独立样本,(Y1,Y2,……,Yn)来自Y的一个独立样本,设统计量 F=\frac{\frac{\sum_{1}^{n_{1}}{X_{i}^{2}}}{n_{1}}}{\frac{\sum_{1}^{n_{2}}{Y_{i}^{2}}}{n_{2}}},称统计量F服从自由度n1和n2、非中心参数δ=nμ^2的非中心F分布,即为F~F(n1,n2,δ)。
2、什么是F检验?
F检验,又叫方差比率检验、方差齐性检验、方差分析ANOVA,是一种在零假设下统计服从F分布的检验。用于判断两个及以上的样本的方差是否有差别的显著性检验。
t检验就需要F检验来验证是否方差齐,只有方差齐了,t检验的结果才反应两组数据是否有差异;如果方差不齐,就会把组内差异也考虑进去。
同时,t检验只适合一个或两个样本的检验,而F检验适用于两个或多个样本的检验。
F检验的原理认为不同处理组的均数间的差别来源两个:一是不同的处理造成的差异,称为组间差异,用变量在各组的均值与总均值之偏差的平方和的总和表示,即为SSA,其中组间自由度dfb=组数-1;二是随机误差,如个体间的差异等等,称为组内差异,用变量在各组的均值与该组内变量值之偏差平方和的总和表示,记为SSE,其中组内自由度dfw=样本总数-组数。
同时,用均方(离差平方和除以自由度)代替离差平方和以消除各组样本数不同的影响,方差分析就是用组间均方除以组内均方的差,再与F检验标准值比较;若F接近标准值则说明各组均值间差异没有统计学意义,若F远大于标准值,则说明各组均值间的差异有统计学意义。
检验统计量F=组间均方/组内均方=(组间离差平方和/组间自由度)/(组内离差平方和/组内自由度)= \frac{\frac{SSA}{dfa}}{\frac{SSE}{dfe}}
3、F检验的前提条件?
(1)总体均值未知
(2)样本来自于正态总体
4、F检验的类型
(1)单因素方差分析
(i)定义
单因素方差分析,是指方差分析中只涉及一个分类型自变量对数值型变量的影响,如不同行业被投诉次数的均值是否相等。
H0:μ1=μ2=……=μi=……=μk(即自变量对因变量没有显著影响),H1:μi(i=1~k)不全相等(即自变量对因变量有显著影响)
检验统计量值F=MSA/MSE~F(k-1,n-k),其中,k表示组数,n表示全部观测值个数,k-1表示组间自由度,n-k表示组内自由度;
组间均方MSA=组间平方和/组间自由度=SSA/(k-1);
组内均方MSE=组内平方和/组内自由度=SSE/(n-k),注意这里的组内平方和,是所有组的所有平方和的总和;
总平方和SST=组间平方和SSA+组内平方和SSE。SSE是对随机误差大小的度量,反映了除了自变量对因变量的影响之外,其他因素对因变量的总影响,也称残差变量;SSA是对随机误差和系统误差大小的度量,反映了自变量对因变量的影响;SST是对全部数据总误差程度的度量,反映自变量和残差变量的共同影响,SST自由度为n-1。
R反映自变量和因变量之间的关系强度,而 R^{2}=\frac{SSA}{SST} 。
通过自由度k-1和n-k可以查找F分布表得到临界值 F_{α}(k-1,n-k)。 F>F_{α} 则拒绝原假设,否则不能拒绝原假设。
通过最小显著差异方法LSD,可用来判断结论中的差异是由于变量中哪些水平的差异造成;
检验统计量是相互间的均值之差 \bar{x}_{i}-\bar{x}_{j} ;
而是否拒绝原假设,则有均值之差与LSD结果比较, LSD=t_{α/2}*\sqrt{(MSE(\frac{1}{n_{i}}+\frac{1}{n_{j}}))} ,ni和nj分别为第i个水平样本和第j个水平样本的样本量(个数);
如果 \left| \bar{x}_{i}-\bar{x}_{j} \right|>LSD 则拒绝原假设,否则不拒绝原假设。
(ii)python实现单因素方差分析
补充:scipy.stats的f模块可调用各种显著性水平下,对应的两个自由度的F临界值。
scipy.stats.f.ppf(1-显著性水平,自由度1,自由度2)
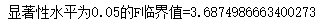
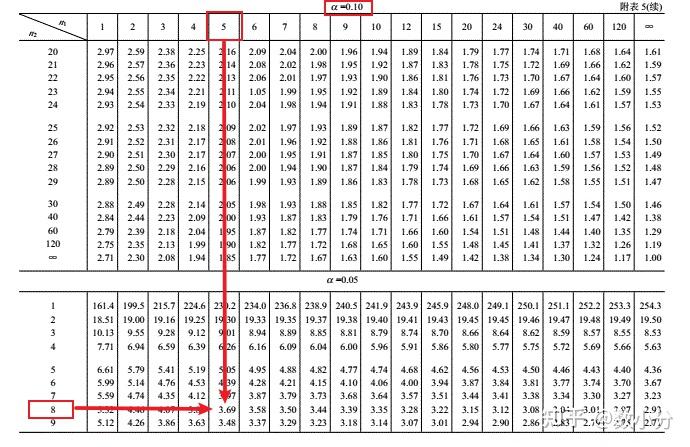
①可使用scipy.stats的f_oneway实现单因素的方差分析
scipy.stats.f_oneway(*sanples,axis=0)
sample1,sample2……数组形式的样本值,必须至少两个数组;axis默认为0。返回F检验值和P值。
from scipy.stats import f_oneway
data1=[29.6,24.3,28.5,32.0]
data2=[27.3,32.6,30.8,34.8]
data3=[5.8,6.2,11.0,8.3]
data4=[21.6,17.4,18.3,19.0]
data5=[29.2,32.8,25.0,24.2]
f,p=f_oneway(data1,data2,data3,data4,data5)
print("F检验值={},p值={}".format(f,p))
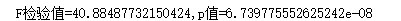
②使用statsmodels的ols模块,以及statsmodels.stats.anova.anova_lm模块共同进行单因素方差分析
ols(formula,data)前者是回归相关公式后者是使用数据,公式中使用~,左边为因变量,右边为自变量,自变量之间用+连接,+0表示模型没有常数项,~后面的名称都要是表中的列名,:表示前后变量有交互作用;
fit()用来计算一组数据的特征值,包括均值、方差、中位数等固定属性
scipy.stats.anova_lm函数可生成一个或多个拟合线性模型的方差分析表。
import pandas as pd
from statsmodels.stats.anova import anova_lm
from statsmodels.formula.api import ols
data1=[29.6,24.3,28.5,32.0]
data2=[27.3,32.6,30.8,34.8]
data3=[5.8,6.2,11.0,8.3]
data4=[21.6,17.4,18.3,19.0]
data5=[29.2,32.8,25.0,24.2]
#由于5组数据都是一个变量的不同水平,需要合并成一列数据,方便算法计算
num=sorted(["d1","d2","d3","d4","d5"]*4) #扩展4行名称并排序
data=data1+data2+data3+data4+data5 #将5组数据合并成一个list
df=pd.DataFrame({"num":num,"data":data})
mod=ols("data~num",data=df).fit()
res=anova_lm(mod,typ=2) #2表示dataframe,有1,2,3这三个字,2代表dataframe格式
print(res)
#df表示自由度,sum_sq表示离差平方和,F表示F检验值,PR表示p值,residul表示残差

(2)无重复的双因素方差分析
(i)定义
无重复双因素方差分析,是每一个组合因素只进行一次独立试验,每个格子只有一个值;有两个影响因素且两个因素对因变量的影响是独立的,即无交互作用。
两个因素分别称为行因素和列因素,行因素k个水平,列因素r个水平,共有kr个观察数据;
对行因素做假设,H0:μ1=μ2=……=μi=……=μk(即行因素自变量对因变量没有显著影响),H1:μi(i=1~k)不全相等(即行因素自变量对因变量有显著影响)
对列因素做假设,H0:μ1=μ2=……=μj=……=μk(即列因素自变量对因变量没有显著影响),H1:μj(j=1~k)不全相等(即列因素自变量对因变量有显著影响)
构造检验统计量
需要分别确定检验行因素和列因素的统计量,与单因素方差构造统计量方法一样。
SST表示总误差平方和,自由度为kr-1;SSR表示行因素误差平方和,自由度为k-1;SSC表示列因素误差平方和,自由度为r-1;SSE是随机误差平方和,自由度为(k-1)*(r-1);SST=SSR+SSC+SSE, MSR=\frac{SSR}{k-1} ,MSC=\frac{SSC}{r-1} , MSE=\frac{SSE}{(k-1)(r-1)} 。
行因素和列因素两个自变量对因变量的联合效应为SSR+SSC;联合效应与总平方和的比重定义为 R^{2}=\frac{SSR+SSC}{SST} ,平方根R反映了两个自变量合起来与因变量之间的关系强度。
行因素检验统计量 F_{R}=\frac{MSR}{MSE}\sim~F(k-1,(k-1)(r-1))
列因素检验统计量 F_{C}=\frac{MSC}{MSE}\sim~F(r-1,(k-1)(r-1))
统计决策
通过显著性水平和两个自由度查F分布表得到临界值 F_{\alpha} ;F_{R}>F_{\alpha}则拒绝原假设;F_{C}>F_{\alpha}则拒绝原假设。
R^{2} =84%表示两个自变量合起来总统解释了因变量差异的84%,其他因素(残差变量)只解释了因变量差异的16%;而R=0.92表名两个自变量合起来与因变量间有较强的关系。
(ii)python实现无重复双因素方差分析
使用statsmodels的ols模块,以及statsmodels.stats.anova.anova_lm模块共同进行无重复的双因素方差分析
import pandas as pd
from statsmodels.stats.anova import anova_lm
from statsmodels.formula.api import ols
data1=[29.6,24.3,28.5,32.0]
data2=[27.3,32.6,30.8,34.8]
data3=[5.8,6.2,11.0,8.3]
data4=[21.6,17.4,18.3,19.0]
data5=[29.2,32.8,25.0,24.2]
data=[data1,data2,data3,data4,data5]
df=pd.DataFrame(data,columns=["广告1","广告2","广告3","广告4"],index=["价格1","价格2","价格3","价格4","价格5"])
#dataframe格式不适合ols的使用,需要转换格式
a=df.stack().reset_index()
a.columns=["价格","广告","销量"]
mod=ols("销量~价格+广告",data=a).fit()
res=anova_lm(mod,typ=2)
print(res)

(3)可重复的双因素方差分析
(i)定义
可重复双因素方差分析,每一个组合因素进行多次试验,每个格子不止一个值;有两个影响因素且除了两个因素对因变量的单独影响外,两个因素的搭配还会对因变量产生新的一种影响,即有交互作用。如某个地区对某种品牌的彩电有特殊偏好。
步骤类似于无重复的双因素方差分析,此外还需要加上交互作用的影响变量; 行变量i有k=2个水平,每个水平有m=5行,列变量j有r=2个水平,观察总数n=20;
\bar{X}=\frac{1}{krm}\sum_{1}^{k}{\sum_{1}^{r}{\sum_{1}^{m}{x_{ijl}}}} ,表示全部n个观测值的总均值;
\bar{X}_{i··}=(1/rm)\sum_{1}^{r}{\sum_{1}^{m}{x_{ijl}}} ,表示行因素第i个水平的样本均值;
\bar{X}_{·j·}=(1/km)\sum_{1}^{k}{\sum_{1}^{m}{x_{ijl}}} ,表示列因素第j个水平的样本均值;
\bar{X}_{ij·}=(1/m)\sum_{1}^{m}{x_{ijl}} ,表示行因素第i个水平和列因素第j个水平的样本均值;xijt对应行因素第i个水平、列因素第j个水平的第l行的观测值。
总平方和 SST=\sum_{1}^{k}{\sum_{1}^{r}{\sum_{1}^{m}{(x_{ijl}-\bar{x})^{2}}}}
行变量平方和 SSR=rm\sum_{1}^{m}{(x_{i··}-\bar{x})^2}
列变量平方和 SSC=km\sum_{1}^{r}{(\bar{x}_{·j·}-\bar{x})^2}
交互作用变量平方和 SSRC=m\sum_{1}^{k}{\sum_{1}^{r}{(\bar{x}_{ij·}-\bar{x}_{i··}-\bar{x}_{·j·}-\bar{x})^2}}
误差平方和SSE=SST-SSR-SSC-SSRC;
(ii)python实现可重复双因素方差分析
import pandas as pd
from statsmodels.stats.anova import anova_lm
from statsmodels.formula.api import ols
data1=[29.6,24.3,28.5,32.0]
data2=[27.3,32.6,30.8,34.8]
data3=[5.8,6.2,11.0,8.3]
data4=[21.6,17.4,18.3,19.0]
data5=[29.2,32.8,25.0,24.2]
data6=[29.2,32.8,25.0,24.2]
data=[data1,data2,data3,data4,data5,data6]
df=pd.DataFrame(data,columns=["广告1","广告2","广告3","广告4"],index=["价格1","价格2","价格3","价格4","价格5","价格6"])
#dataframe格式不适合ols的使用,需要转换格式
a=df.stack().reset_index()
a.columns=["价格","广告","销量"]
#这里形成可重复双因素数据
a.loc[a["价格"]=="价格5","价格"]="价格1"
a.loc[a["价格"]=="价格6","价格"]="价格3"
mod=ols("销量~价格+广告+价格:广告",data=a).fit()
res=anova_lm(mod,typ=2)
print(res)
原文地址:https://zhuanlan.zhihu.com/p/557799046 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-12 22:39
发表于 2025-3-12 22:39
 提升卡
提升卡


