金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
谢邀,上面很多老师同学都说得很好,我发表下拙见。以下除非申明,下划线均是我加的。
首先看看生物实验的可重复性到底是个怎样的情况。当然不是100%能重复的,不然每天那么多retracted的paper,而且得知道一般high-profile的杂志上的paper重复得才多,发国内XX学报上的文章会有很多人去重复么?(这里补充下,misconduct占据retracted papers的大多数,详情可参考
http://www.pnas.org/content/early/2012/09/27/1212247109)
估计很多人都知道这篇文章:Ioannidis, J. P.
PLOS Medicine: Why Most Published Research Findings Are False PLoS Med. 2, e124 (2005).
像这样的文章其实中心思想都差不多,发现发表的文章里positive results的比例惊人地高,以至于在统计学上是很不靠谱。下面再介绍其他的文章。
根据此篇文章的说法,为了发表并且生存,存在种种倾向于positive results的bias。体现为单打独斗,没有交叉验证(顺便说句,有些实验譬如PCR做克隆这种玩意,做出来就做出来了,显然没必要验证。有些实验比如行为学实验,你一不做双盲二样本量少得可怜,统计也随便搞个t-test试试那些自己认为“好”的答案,即使p小于0.001又怎么样呢。再喊个人来重复,重复不出来就说没做好,呵呵呵。所以,严谨的态度很重要,为了凑个好的结果而乱搞,你还不如别干这行了。不足的样本量(有时甚至有挑选数据的现象)和似是而非甚至生拉硬拽的统计分析方法,是常见的导致irreproducible results的原因)这里此文作者提出几个Corollaries:
Corollary 1: The smaller the studies conducted in a scientific field, the less likely the research findings are to be true.
Corollary 2: The smaller the effect sizes in a scientific field, the less likely the research findings are to be true.
Corollary 3: The greater the number and the lesser the selection of tested relationships in a scientific field, the less likely the research findings are to be true.
Corollary 4: The greater the flexibility in designs, definitions, outcomes, and analytical modes in a scientific field, the less likely the research findings are to be true.
Corollary 5: The greater the financial and other interests and prejudices in a scientific field, the less likely the research findings are to be true.
Corollary 6: The hotter a scientific field (with more scientific teams involved), the less likely the research findings are to be true.
然后作者得出两个结论:
Most Research Findings Are False for Most Research Designs and for Most Fields.
Claimed Research Findings May Often Be Simply Accurate Measures of the Prevailing Bias.
怎样解决这些问题呢,作者提出:
Better powered evidence, e.g., large studies or low-bias meta-analyses, may help, as it comes closer to the unknown “gold” standard.
Second, most research questions are addressed by many teams, and it is misleading to emphasize the statistically significant findings of any single team. What matters is the totality of the evidence.
Finally, instead of chasing statistical significance, we should improve our understanding of the range of
R values—the pre-study odds—where research efforts operate。
然后可以再移步看看这篇文章:
Believe it or not: how much can we rely on published data on potential drug targets? : Article : Nature Reviews Drug Discovery
Nature Reviews Drug Discovery 10, 712 (September 2011) | doi:10.1038/nrd3439-c1
Florian Prinz, Thomas Schlang & Khusru Asadullah
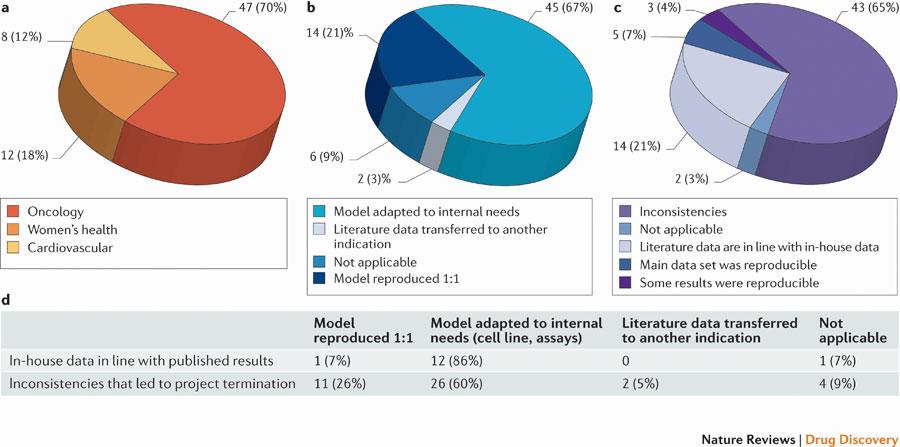
“We received input from 23 scientists (heads of laboratories) and collected data from 67 projects, most of them (47) from the field of oncology. This analysis revealed that only in ~20–25% of the projects were the relevant published data completely in line with our in-house findings (
Fig. 1c). In almost two-thirds of the projects, there were inconsistencies between published data and in-house data that either considerably prolonged the duration of the target validation process or, in most cases, resulted in termination of the projects because the evidence that was generated for the therapeutic hypothesis was insufficient to justify further investments into these projects.”
“Furthermore, despite the low numbers, there was no apparent difference between the different research fields. Surprisingly, even publications in prestigious journals or from several independent groups did not ensure reproducibility. Indeed, our analysis revealed that the reproducibility of published data did not significantly correlate with journal impact factors, the number of publications on the respective target or the number of independent groups that authored the publications.”
“The challenge of reproducibility — even under ideal conditions — has also been highlighted, indicating that even in an optimal setting (the same laboratory, the same people, the same tools and the same assays, with experiments separated by 5 months), there were substantial variations, as the intra- and interscreen reproducibility of two genome-scale small interfering RNA screens was influenced by the methodology of the analysis and ranged from 32–99%”
"Among the more obvious yet unquantifiable reasons, there is immense competition among laboratories and a pressure to publish. It is conceivable that this may sometimes result in negligence over the control or reporting of experimental conditions (for example, a variation in cell-line stocks and suppliers, or insufficient description of materials and methods). "
这里还有篇类似的文章,就不详细介绍了:
http://www.nature.com/nrd/journal/v10/n5/full/nrd3439.htmlNature Reviews Drug Discovery 10, 328-329 (May 2011) | doi:10.1038/nrd3439
John Arrowsmith
为毛出错?为毛重复不了?上面已经提到很多时候为了生存而出现的糟糕的实验设计(flexible,呵呵),然后灵活性非常大的materials & methods的介绍,然后select data(flexible吧),然后就是同样flexible的统计分析。当然不见得写一篇文章时提到的所有问题都会出现,但欢迎对号入座,全部出现者请留言发表感想。
下面这个技术性比较强的文章介绍了neuroscience field里面paper不强的统计结果说服力,当然后面还有很多质疑这篇文章以及作者的回应,有兴趣的同学可以自行寻找:
http://www.nature.com/nrn/journal/v14/n5/full/nrn3475.htmlNature Reviews Neuroscience 14, 365-376 (May 2013) | doi:10.1038/nrn3475
Katherine S. Button et. al.
"Three main problems contribute to producing unreliable findings in studies with low power, even when all other research practices are ideal. They are: the low probability of finding true effects; the low positive predictive value (PPV; see
Box 1 for definitions of key statistical terms) when an effect is claimed; and an exaggerated estimate of the magnitude of the effect when a true effect is discovered."
Summary
- Low statistical power undermines the purpose of scientific research; it reduces the chance of detecting a true effect.
- Perhaps less intuitively, low power also reduces the likelihood that a statistically significant result reflects a true effect.
- Empirically, we estimate the median statistical power of studies in the neurosciences is between ~8% and ~31%.
- We discuss the consequences of such low statistical power, which include overestimates of effect size and low reproducibility of results.
- There are ethical dimensions to the problem of low power; unreliable research is inefficient and wasteful.
- Improving reproducibility in neuroscience is a key priority and requires attention to well-established, but often ignored, methodological principles.
- We discuss how problems associated with low power can be addressed by adopting current best-practice and make clear recommendations for how to achieve this.
还有例子,比如这个
Carp, J.
The secret lives of experiments: Methods reporting in the fMRI literature. Neuroimage 63, 289–300 (2012).
This article reviews methods reporting and methodological choices across 241 recent fMRI studies and shows that there were nearly as many unique analytical pipelines as there were studies. In addition, many studies were underpowered to detect plausible effects.
呵呵,还真的是一千个人眼里有一千个哈姆莱特啊。当然我不是做这个领域的,但好像得到的raw data都是测量一个指标吧,有必要出现这么多分析方法么?欢迎业内人士拍砖。
下面再送出我部分“珍藏”的文章:
Evaluation of the Potential Excess of Statistically Significant Findings in Published Genetic Association Studies: Application to Alzheimer's DiseaseAm. J. Epidemiol. (2008) 168(8): 855-865.doi: 10.1093/aje/kwn206
Systematic survey of the design, statistical analysis, and reporting of studies
Journal of Cerebral Blood Flow & Metabolism (2011) 31, 1064–1072; doi:10.1038/jcbfm.2010.217; published online 15 December 2010
PLOS ONE: A Survey on Data Reproducibility in Cancer Research Provides Insights into Our Limited Ability to Translate Findings from the Laboratory to the Clinic
PLoS ONE 8(5): e63221. doi:10.1371/journal.pone.0063221
PLOS ONE: Systematic Review of the Empirical Evidence of Study Publication Bias and Outcome Reporting Bias
PLoS ONE 3(8): e3081. doi:10.1371/journal.pone.0003081
PLOS Medicine: Can Animal Models of Disease Reliably Inform Human Studies?
PLoS Med 7(3): e1000245. doi:10.1371/journal.pmed.1000245
http://www.plosbiology.org/article/info%3Adoi%2F10.1371%2Fjournal.pbio.1000344
PLoS Biol 8(3): e1000344. doi:10.1371/journal.pbio.1000344
**********以下是个人情感的分割线,不喜请无视**********
生物,我曾经热爱的领域,从小学时候翻我爸同事的初中教材开始。后来高中义无反顾地报了生物竞赛(为毛为毛为毛?因为我觉得我自己以后就一直做生物了(cursing self, how brilliant!)数学物理计算机太差(小时候千万不能自卑啊,放弃数理化计算机一生做生物不幸福!),化学么又不想每天听我老爸唠叨(我爸教化学))。然后是省赛差0.5分一等奖,没保送,考了SCU,继续学生物(万劫不复,失策),然后保送号称要打造“top 5”的CAS某所(没出去,再次失策),现在,终于想明白,老子不干了!
原因,上面已经有不少了,以前觉得神圣无比的生物实验原来如此,呵呵呵,感觉就像你的女神原来turn out是快餐800,包夜1500的货色。然后至少个人得到的训练根本和市场脱节。所谓实验技能,呵呵,你照着protocol用commercial kit做实验很了不起么。然后所谓数据分析,就是用excel算t-test,根本就不管前提条件。每天卖苦力,然后看着flexible的种种,身心俱疲。我才不要喜当爹!
这里有几篇文章,描述了学术界的一些现状,供大家参考。
Publish-or-perish: Peer review and the corruption of scienceThe Corruption of Science in America -- Sott.net
Biomedical burnout : Naturejobs
现在想想,生物重复性差,说明根本就没有标准化规范化可言,一部分wet lab还停留在类似炼金术的时候,做不出来就简单重复呗,偶尔有一个positive的好赶紧收着,要是不严谨点就干脆用着一个好了。所谓某人做实验做得好,为毛别人无法重复?还是同一个实验室的人的呢?这种手工匠人式的搞法,很多时候搭配了“灵活的”设计,数据收集和分析,所以,我呵呵吧。
以后应该是数学物理基础好的人往生物领域猛扎的时代,DNA的编辑,细胞内反应的model,甚至model整个brain的活动......是这些只知PCR,western,CoIP的wet lab的人能做的么?做这些事情需要phd degree么,呵呵。传统的hypothesis driven的wet lab的日子还剩多少,拭目以待吧。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-3 08:06
发表于 2025-3-3 08:06


 提升卡
提升卡
 发表于 2025-3-3 08:09
发表于 2025-3-3 08:09



